大一统目标跟踪
跟踪中的任务主要有:
- 多目标跟踪(Multi Object Tracking, MOT)
- 单目标跟踪(Single Object Tracking, SOT)
- 多目标跟踪分割(Multi Object Tracking and Segmentation, MOTS)
- 视频目标分割(Video Object Segmentation, VOS)
这里,我暂时先不关心分割的任务。以下是MOT和SOT的对比:
| Tasks | Reference | Class | Tracks per video | Typical Inputs | Representative Methods |
|---|---|---|---|---|---|
| MOT | No | specific | Tens or hundreds | High-resolution Whole Image | Detection+Association |
| SOT | Initial box | agnostic | One | Small search region | One-Shot Detection |
可以看到两个任务之间的gap还是比较大的,总结一下,阻碍SOT和MOT两个任务统一的主要有三座大山:
- 被跟踪目标的属性不同(参考帧给定的一个,任意类别的目标 VS 几十几百个特定类别的目标);
- SOT和MOT关注的对应关系不同(SOT关注目标和背景的区分,MOT关注目标和轨迹的对应);
- 不同的输入(SOT输入为小的搜索范围,以节省计算量和消除潜在的干扰;MOT输入为高分辨率的全图,以尽可能检测到所有实例)。
大一统的目标跟踪这里是指,仅需要一套模型及参数,就可以在各个任务上取得优异的表现。我将介绍两个工作的这部分内容,看看它们是怎么翻过这些大山的。
1. Unicorn,ECCV2022,Oral
Towards Grand Unification of Object Tracking
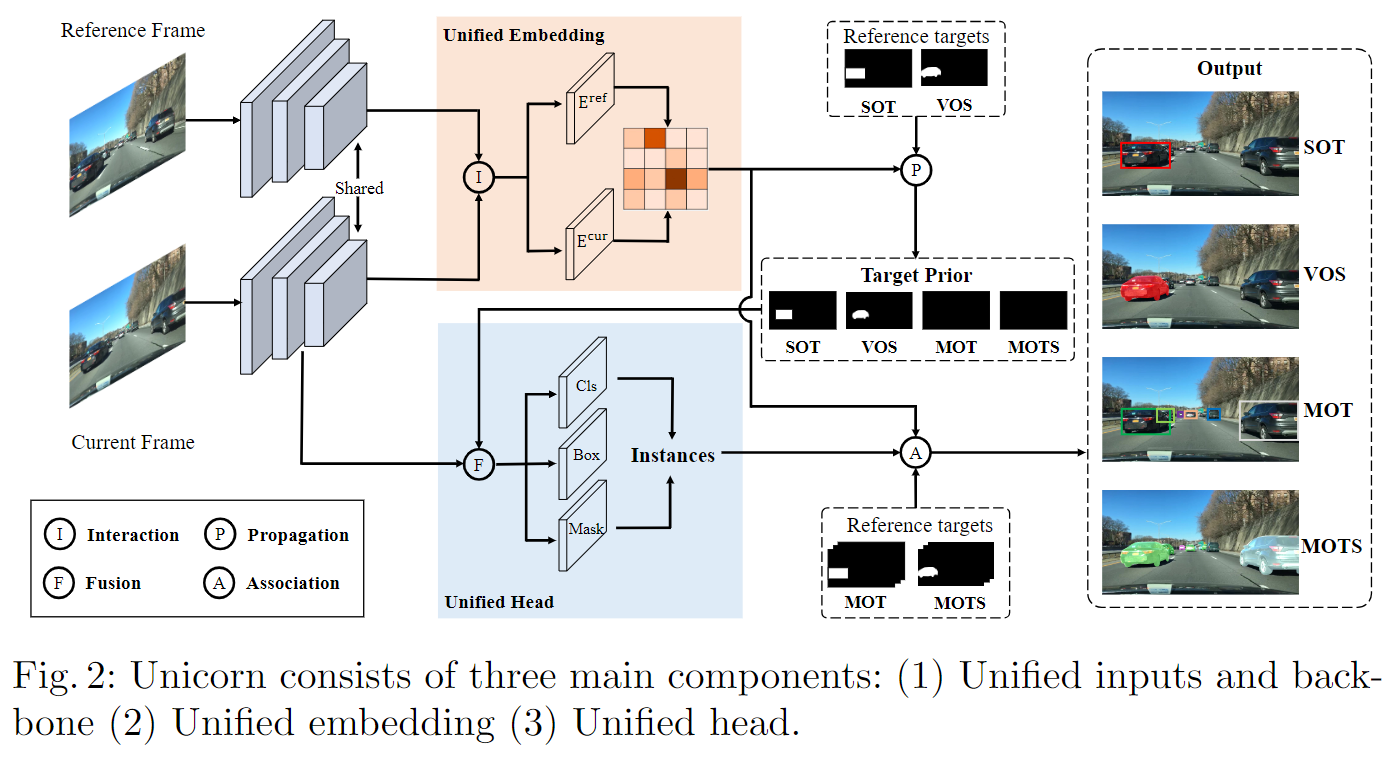
采用YOLOX作为baseline结构;
采用高分辨率全图作为输入,对于SOT参考帧是第一帧,对于MOT参考帧是当前帧的前一帧(第一帧的参考帧设为第一帧本身);
- Interaction方法,代码给出三种实现方式,分别是“deform”:使用deformable transformer encoder、“full”:使用普通transformer encoder、以及“conv”:使用两层卷积。默认使用“deform”,将参考帧和当前帧的特征展平后加入位置编码送入encoder,再把输出结果重新拼回原来的shape。
- Fusion 方法代码中给出sum和mul两种,默认使用带有可学习权重beta的sum,即$x=x+(m \times \beta)$,x为特征,m为mask.
- Propagation 操作是指,使用参考帧的gt map与相似度矩阵做矩阵乘法,得到的是gt传播到当前帧的结果。
- Association 是指ByteTrack或者QDTrack的关联策略。
SOT的关联矩阵是hw x hw 的(其中h=H/s, w=W/s),计算的是像素级的对应关系;MOT的关联矩阵是M x N的,计算的是目标级的对应关系。其中M代表参考帧中的gt目标个数,N代表当前帧中的gt目标个数,每个目标用它中心点的embedding特征来代表,矩阵乘法计算相似度矩阵(M, C) * (C, N) -> (M, N)得到。所以说,MOT的关联矩阵是SOT的子矩阵;
关联损失函数设计,对于SOT是关联矩阵的像素级预测损失,使用Dice loss;对于MOT的矩阵,使用对比学习的思想,同一目标处标签为1,不同目标处标签为0,使用交叉熵损失;总的损失是关联损失+检测损失;
预测头设计,使用一个目标mask先验m与预测头特征x进行Fusion,SOT有mask,MOT没有;
训练流程,1:1随机采样SOT和MOT的数据,SOT和MOT交替训练
2. UniNEXT,CVPR2023
Towards Universal Instance Perception
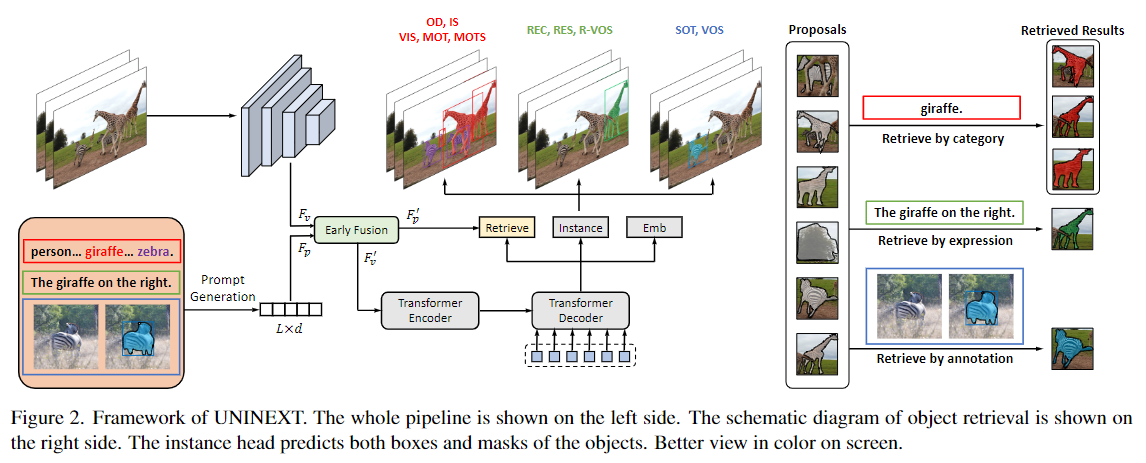
换用了Deformable DETR作为baseline结构,当使用resnet50作为backbone时,Deformable DETR和YOLOX性能接近,但是当换作ConvNeXt-Large作为backbone时,Deformable DETR可以取得显著的更大的性能提升。
通过prompt生成模块,输入类别词串/句子/标注,生成提示词的特征$F_p$
通过ResNet或者ConvNeXt骨干网络,得到输入图片的特征$F_v$
通过Early Fusion模块,它由双向的Cross-Attention组成,融合提示词的特征$F_p$和图像提取的特征$F_v$,得到融合后的$F^{\prime}_p$和$F^{\prime}_v$
$F^{\prime}_v$作为Deformable DETR检测网络的特征输入,可以得到一组目标Proposals输出。此时,用$F^{\prime}_p$作为查询去检索需要的proposal,即计算Proposals实例特征与$F^{\prime}_p$的相似度,选取相似度高于阈值或者topk作为最终结果。
值得注意的是,该网络中没有分类头,因此可以在不同数据集之间灵活的切换。
训练分为三个阶段,第一步使用object365进行大规模预训练,进行检测和分割任务;第二步在多个图片benchmark组合成的数据集上训练;第三步在多个视频benchmark组合成的数据集+第二步数据集变成伪视频上训练;

