Prompt 工程
ChatGPT 已经广泛用于各行各业提高工作效率。然而,不同的引导词(prompt)提示下,同一模型的输出结果可能大相径庭,好的prompt能释放模型的潜力,得到更有用的输出。本文提供了一些方法论和常用 prompt 示例。本文持续更新,欢迎在评论区踊跃交流经验~
LLM评测
1. Open LLM Leaderboard(英文)
Open LLM Leaderboard中包含有下列Benchmark:
所有能力
- 通用&数学&code——MT-Bench,由80个高质量的多轮对话问题组成的基准,旨在测试多轮对话和指令遵循能力,共包含8个常见的用户提示类别:writing 写作、roleplay 角色扮演、extraction 提取、reasoning 推理、math 数学、coding 编程、知识I(stem)和 知识II(humanities 人文/社会科学)。对于每个类别,手动设计了10个多轮的问题,每一轮有2个问题。
OneChart—让VLM知之为知之,不知为不知
论文:OneChart: Purify the Chart Structural Extraction via One Auxiliary Token
主页及demo:https://onechartt.github.io/
《论语》中说:“知之为知之,不知为不知,是知也”。从神经网络兴起以来,人们就没有停止过对这种黑盒模型应用在生产环境的担心。在AI 1.0中大部分模型还至少会输出一个置信度得分可供参考;然而对于AI2.0时代的VLMs来说,所有的结果以文本的形式吐出,这加重了人们对模型安全性的焦虑。让模型知道自己的能力边界,不要产生致命错误,这点十分必要,也是目前的难点。
VLM常见Dataset和Benchmark
Vision Encoders in VLM
SAM 好比在视网膜层面,能力是很low-level的,举个例子它可以对图片信息进行简单的切分,但它不知道左边的一坨像素和右边的一坨像素是一个品种的狗。DINOv2好比大脑中某块视觉区,好比刚出生不久的婴儿,它是纯视觉的,可以完成视觉层面的目标聚类,知道左边的一坨像素和右边的一坨像素是一种东西,但没有语言系统不知道这种东西叫“金毛犬”。CLIP就是更近一步,实现了视觉和语言的关联,好比5岁的小孩;然而由于数据、训练方式、输入分辨率等原因,CLIP没正经读过书看过图表,所以在做dense OCR任务时Vary自己训了个encoder,在做chart任务时Onechart也自己训了个encoder,好比让小孩上个学。🐶
Vision encoders百花齐放,与decoders相匹配。当decoder是LLM时,需要LLM能看懂的encoder。
Vision-Language 的 Vision Encoders
1. CLIP 2021.2.26
论文:Learning Transferable Visual Models From Natural Language Supervision(OpenAI in ICML2021)
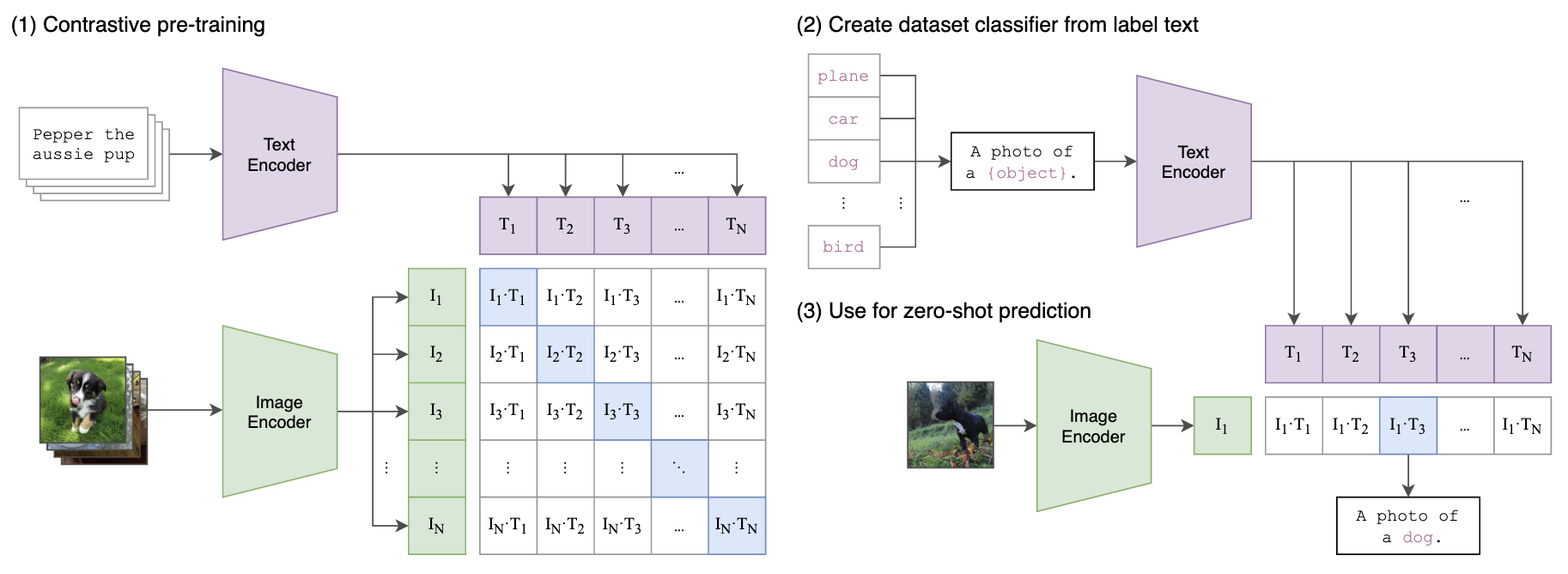
如下图所示,将图片和文本描述通过网络都得到768维的Embedding,其中文本编码器使用transformer,图片编码器使用了ResNet和ViT两种结构进行实验,ViT的有4个模型:输入224px 的 ViT-B/32, ViT-B/16 (196 tokens), ViT-L/14 (256 tokens);输入336px的 ViT-L/14 (576 tokens)。预训练使用了400M(4亿)个图像文本对,每个batch采样三万多个这样的配对,通过对比学习,配对的Embedding位置处为1,非配对处为0进行交叉熵损失训练。
在测试时支持zero-shot推理,如下面右图所示:首先分别获得图像和文本的embedding,对提取的embedding进行归一化用来算相似度image_features /= image_features.norm(dim=-1, keepdim=True), text_features /= text_features.norm(dim=-1, keepdim=True)。通过计算图片Embedding和各个候选("a photo of [cls_name]")的相似度,相似度大于某个阈值或者topk的为输出类别结果。
Vary-toy—年轻人的第一个多模大模型
在上一篇工作 Vary 中,我们第一次提出了CLIP视觉词表在密集感知能力上的不足,并给出了一种简单有效的扩充词表方案。Vary发布后得到了不少朋友的关注(目前已1.2k+ star),但也有不少人因为资源受限运行不了。
考虑到目前开源得很好且性能出色的“小”VLM比较少,我们新发布了“年轻人的第一个多模大模型”——1.8B Vary-toy,并以最大的诚意欢迎各位高校和个人研究者们加入多模态大模型的研究中。当然也欢迎大佬们用它做出有意思的落地应用,把Vary-toy玩起来!
与Vary相比,Vary-toy除了小之外,我们还优化了新视觉词表。解决了原Vary只用新视觉词表做 OCR 的网络容量浪费问题,以及吃不到SAM预训练优势的问题。与Vary-toy同时发布的还有更强的视觉词表网络,其不仅能做文档级 OCR,还能做通用视觉目标检测。
Vary—提升LVLM的dense和细粒度视觉感知能力
论文:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
项目主页:https://varybase.github.io/
Vary表现出了很大的潜力和极高的上限,OCR可以不再需要冗长的pipline,直接端到端输出,且可以按用户的prompt输出不同的格式如Latex 、Word 、Markdown。通过LLM极强的语言先验,这种架构还可以避免OCR中的易错字,比如“杠杆”和“杜杆”等, 对于模糊文档,也有望在语言先验的帮助下实现更强的OCR效果。Vary展现出的强大的OCR能力被戏称为“OCR 终结者”。
Vision Transformer
从ViT开始,Transformer在视觉领域得到应用。为了降低Transformer中softmax attention操作的计算量和显存,Sparse Global Attention被提出和使用,例如在PVT和PVT v2中。另一种策略是Window attention,如Swin Transformer提出一种Shifted Window方法让ViT具有多尺度的能力,并且降低计算量,能接受大分辨率的图片;Cross-Shaped Window attention则有一半的head分别进行纵向和横向的窗口attention;ViTdet则提出一种local attention+global attention的方法解决该问题。还有一种策略是Linear Attention。
Linear Attention(带有线性归一化) 相比 Softmax Attention有两个点不到位,第一个点是Softmax能让大的更大小的更小,而Linear的出来后比较平滑。第二点是Softmax计算出的Attention map是满秩的,而Linear计算出的是不满秩的,也就是说Linear计算出的对于V的选择是过于同质化的。针对这两点,Flatten Transformer(ICCV2023)提出一种改进名为Focused Linear Attention,旨在弥补二者的性能差距,计算方法如下:
$$O=\phi(Q) \phi(K)^T V+\operatorname{DWC}(V) .$$
DWC是depth-wise convolution,其中计算相似度的过程如下:
$$
\begin{gathered}
\operatorname{Sim}\left(Q_i, K_j\right)=\phi_p\left(Q_i\right) \phi_p\left(K_j\right)^T \\
\text { where } \phi_p(x)=f_p(\operatorname{ReLU}(x)), f_p(x)=\frac{\|x\|}{\left\|x^{* * p}\right\|} x^{* * p}
\end{gathered}
$$
$x^{* * p}$ 表示对x逐位取p次方。
不过Flatten Transformer在应用在各种网络上比如Swin-T中的时候也不是所有的都替换,论文实验表示只换前两个stage比较好,超参p=3。比其他Linear Attention好,但是计算量要求不严格时,比Softmax Attention没特别大优势,提速1.5~2倍吧。
多模态大模型 paperlist
本文重点介绍了一些 VLM 早期的代表性工作。其中,CLIP作为视觉语言模型(VLM)的基础和开山之作,创新性提出了ITC对比损失用于对齐图片级视觉和语言Embedding,但它只能完成判断,无法完成生成式任务。之后BLIP的出现补足了生成的能力,后来Flamingo、LLaVA和BLIP2进一步充分利用了LLM的生成能力,这三个工作也代表了将 image embedding 接入到 LLM 的三种典型的 “Adapter” 方法分别是:XAttn (Flamingo)、Q-Former (BLIP2) 和 MLP (LLaVA)。但它们三个都只能生成文字,Emu进一步补足了图片生成的能力,并创新性提出了一种自回归图片tokens的目标。上述模型针对的图片输入都是全图输入,Shikra和chatSpot则提出了可以接受点和框询问特定位置的MLLM,这种能力被称为Referential对话的能力。Donut和Nogat则特别针对OCR任务提出。
⚠️注意:本文信息几乎截止至2023.8.31,部分内容已缺乏时效性,不具备足够的参考价值