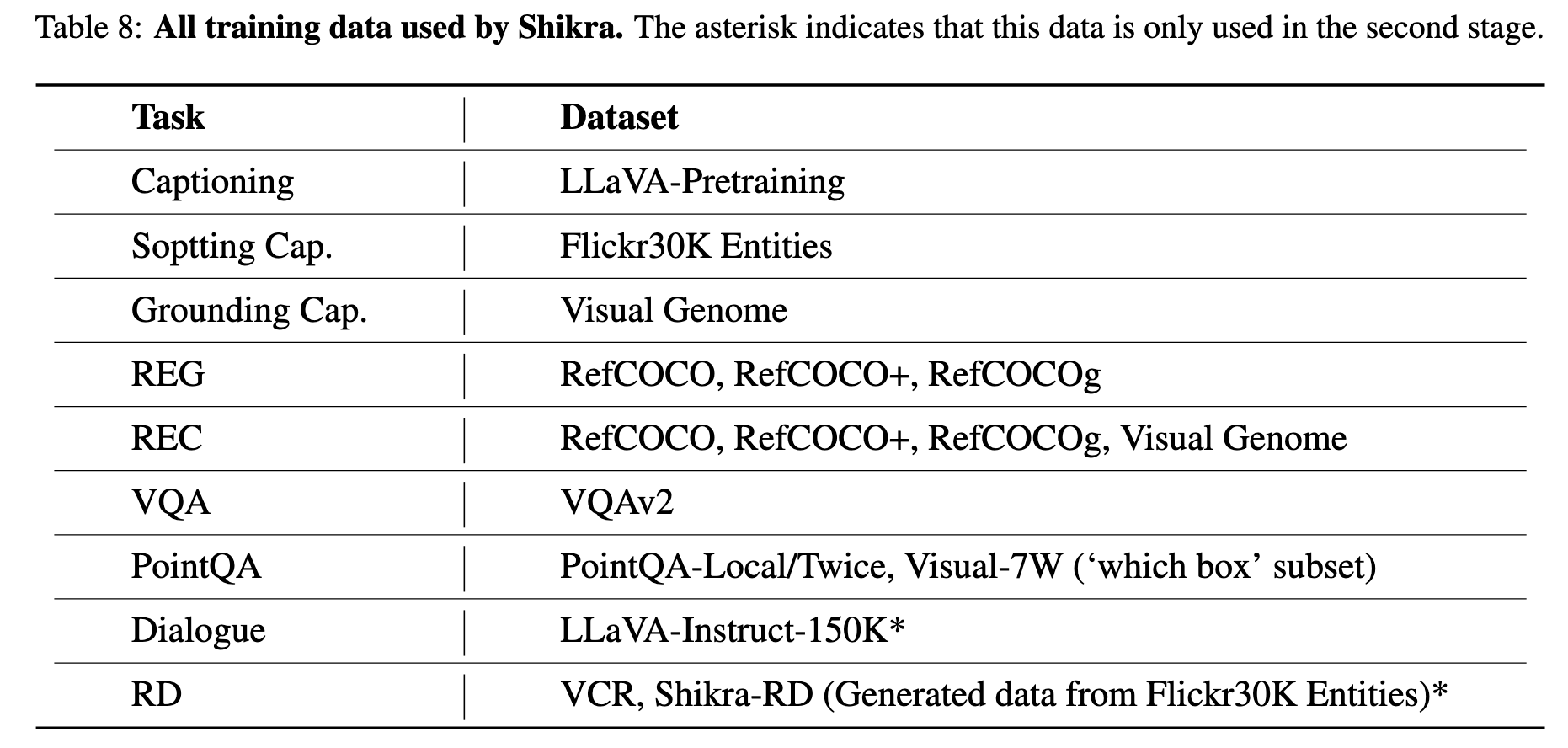
多模态大模型 paperlist
本文重点介绍了一些 VLM 早期的代表性工作。其中,CLIP作为视觉语言模型(VLM)的基础和开山之作,创新性提出了ITC对比损失用于对齐图片级视觉和语言Embedding,但它只能完成判断,无法完成生成式任务。之后BLIP的出现补足了生成的能力,后来Flamingo、LLaVA和BLIP2进一步充分利用了LLM的生成能力,这三个工作也代表了将 image embedding 接入到 LLM 的三种典型的 “Adapter” 方法分别是:XAttn (Flamingo)、Q-Former (BLIP2) 和 MLP (LLaVA)。但它们三个都只能生成文字,Emu进一步补足了图片生成的能力,并创新性提出了一种自回归图片tokens的目标。上述模型针对的图片输入都是全图输入,Shikra和chatSpot则提出了可以接受点和框询问特定位置的MLLM,这种能力被称为Referential对话的能力。Donut和Nogat则特别针对OCR任务提出。
⚠️注意:本文信息几乎截止至2023.8.31,部分内容已缺乏时效性,不具备足够的参考价值
背景知识
多模态大模型MLLM依赖于LLM,常见的LLM包括,主要是英文的:
- ChatGPT-3.5,
- LLaMa-(7B~65B),
- Alpaca-7B (L=512),
- Mistral
- 常用 Vicuna-7B (L=2048, D=4096)、Vicuna-13B (L=2048, D=5120)、
- opt-(125M-175B) (L=2048)
以及支持中文较好的:
- ChatGLM-(6B、12B)、
- Baichuan2-(7B、13B)、
- 常用 Qwen-7B (L=2048)、
- 书生浦语InterLM-20B 等

视觉多模态模型可以实现的任务包括
- Image-to-Image/Text-to-Image/Image+Text-to-Image形式的图像检索
- Image Caption 图像描述
- VQA任务,涵盖的能力包括目标认知、OCR、图表理解、视觉推理、方向理解、几何数学题等。评测形式包括多选题,或者多选题并解释选择原因,或者直接回答。
- Visual Grounding/REC 目标检索定位,给出短语中的物体所在位置,例如“中间的人”,“左边穿红衣服的人”,“蓝车”,“手里拿着球拍的人”。
- 上面任务都是视觉多模理解任务,广义的多模模型还包括图像生成任务,例如:文本驱动的图像生成和图像编辑等。
0. CLIP
CLIP作为视觉语言模型(VLM)的基础和开山之作,创新性提出了ITC对比损失用于对齐图片级视觉和语言Embedding。CLIP可以广泛的应用于图像搜索引擎、聚类、媒体索引、内容审核等领域。
随便抓来一个还能用的demo感受下:
详细见:Vision Encoders in VLM
0. MagicLens
扩展一个图像检索的工作 MagicLens
论文:Self-Supervised Image Retrieval with Open-Ended Instructions(ICML'24 Oral Google DeepMind实习生)
解决的问题:new feature——多模图像检索。当然也可以做图-图检索,或者文-图检索。

数据构建流程如下图,Naturally Occuring lmage Pairs from the Same Web Page,Common Crawl挖掘了36.7M三元组(query image,instruction,target image)。其实用gpt4v做zero-shot也可以甚至更好。

模型结构如下,通过对比学习loss训练,特殊设计的一点是图像自己本身作为negative

1. BLIP 2022.2.15
论文:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation(Salesforce in ICML2022)
项目地址:https://github.com/salesforce/BLIP
CLIP的效果很惊艳,但它只具备判断能力,并不具备文字生成的能力,而BLIP就弥补了这一不足。
数据层面,提出web中本身的image-text pair常常是脏的,提出了一个有效的captioner+filter弱监督流程,以应对网络中图文配对数据中的噪声。
BLIP和ALBEF同一作者团队,借鉴了VLMO的思想(SA参数可以共享),进一步发展了ALBEF:参数共享、增加文本生成decoder分支。

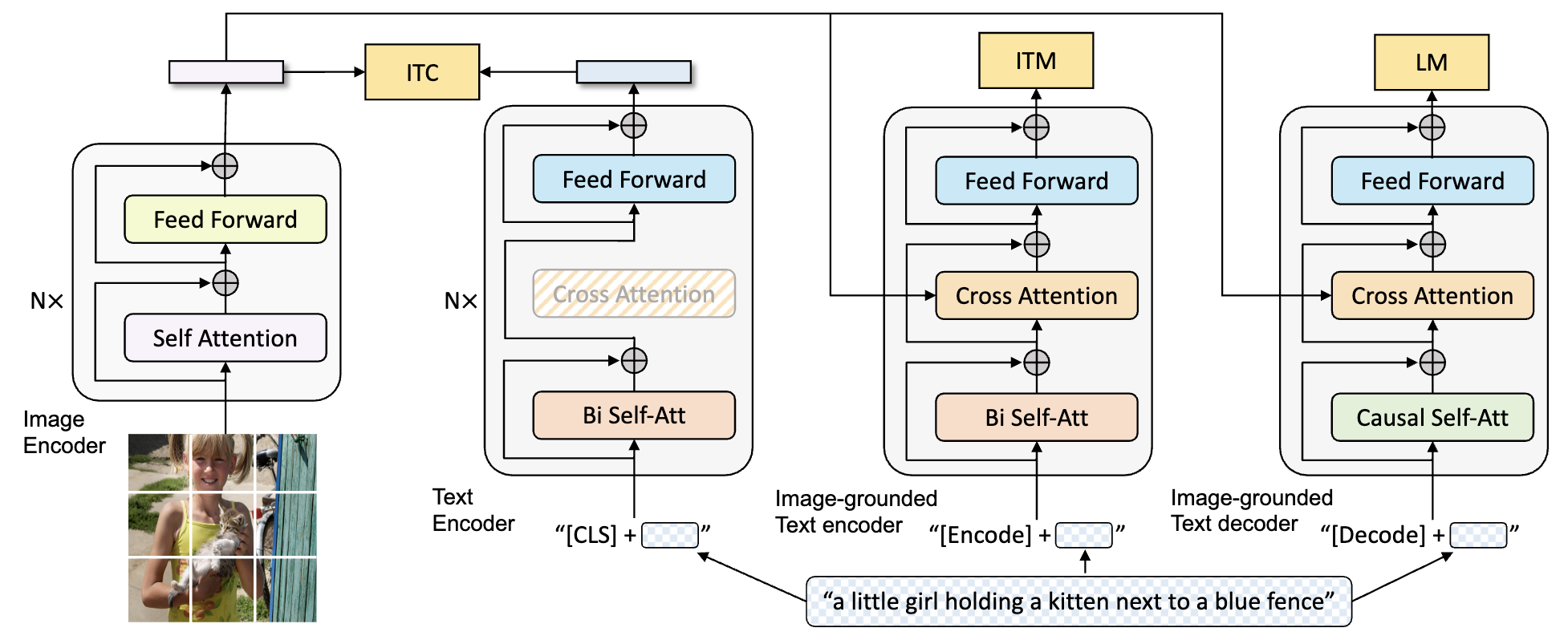
模型的结构如下图,网络整体是类似一个三塔的结构,三塔中Transformer结构块中颜色相同的块代表它们参数是共享的。三个分支分别负责不同的任务,有三个损失,其中 ITC 代表 image-text contrastive 损失,也就是CLIP提出的损失;ITM 代表 image-text matching 损失,对应的是图文匹配的任务;LM 代表language modeling损失,对应的是Image Caption任务。
2. BLIP2 2023.6.15
论文:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models(Salesforce)
在BLIP中,三塔的计算量使得它的运算量比较高,文本端要3次forward,并且要从头训练。后来Flamingo、LLaVA和BLIP2进一步充分利用了LLM的生成能力,这三个工作也代表了将 image embedding 接入到 LLM 的三种典型的 “Adapter” 方法,分别是:XAttn (Flamingo)、Q-Former (BLIP2) 和 MLP (LLaVA)。以及三种不同的训练任务定义和训练流程。
抽象地来看,BLIP模型旨在将图片和文本两个模态的向量往中间拉,使他们处在同一个向量空间。BLIP2提出,我们可以用现有的图像特征提取网络如ViT以及现有的文本特征提取器$\textrm{BERT}_{\textrm{base}}$,让图片和文本向量都呆在他们本身的空间,然后在两个向量空间中架起一个桥梁,这个桥梁就是QFormer,包含 188M 参数量。
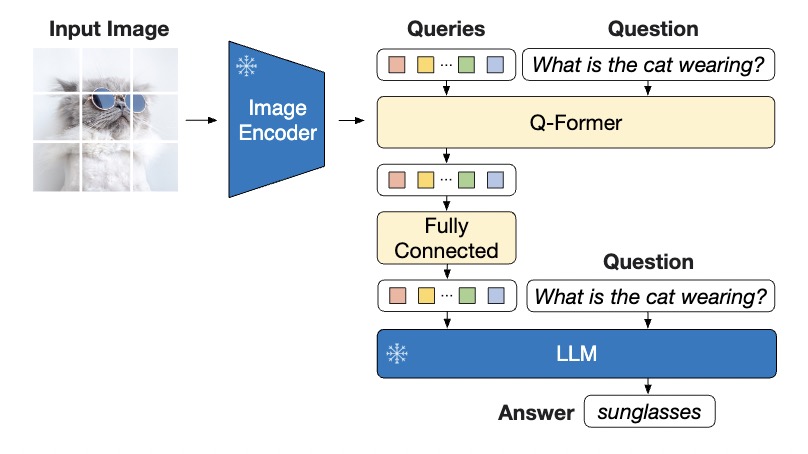

其中vision encoder使用CLIP的 ViT-L/14 或者EVA-CLIP的 ViT-g/14。
Q-Former训练分两个阶段,整个过程Image encoder和LLM冻结不训,第一阶段为视觉语言表示学习。第二阶段为视觉语言生成学习。第一阶段使用image-text pair数据,训练目标有三个:Image-Text Contrastive Learning (ITC)、Image-Grounded Text Generation (ITG)、Image-Text Matching (ITM)。第二阶段使用instructed image-to-text generation数据,训练目标为language modeling loss.
训练数据:129M images,2 captions per image
3. Flamingo 🦩 2022.11.15
论文:Flamingo: a Visual Language Model for Few-Shot Learning(DeepMind in NIPS2022)
Flamingo将图片(或视频)与文本的交错数据作为输入,并生成自由形式的文本作为输出,损失函数使用CE loss。方法的重点在于怎么利用现有的图片Encoder和文本的大模型,将二者缓缓的融合起来。整体结构如下图所示。本文的创新点就是两个紫色的部分。
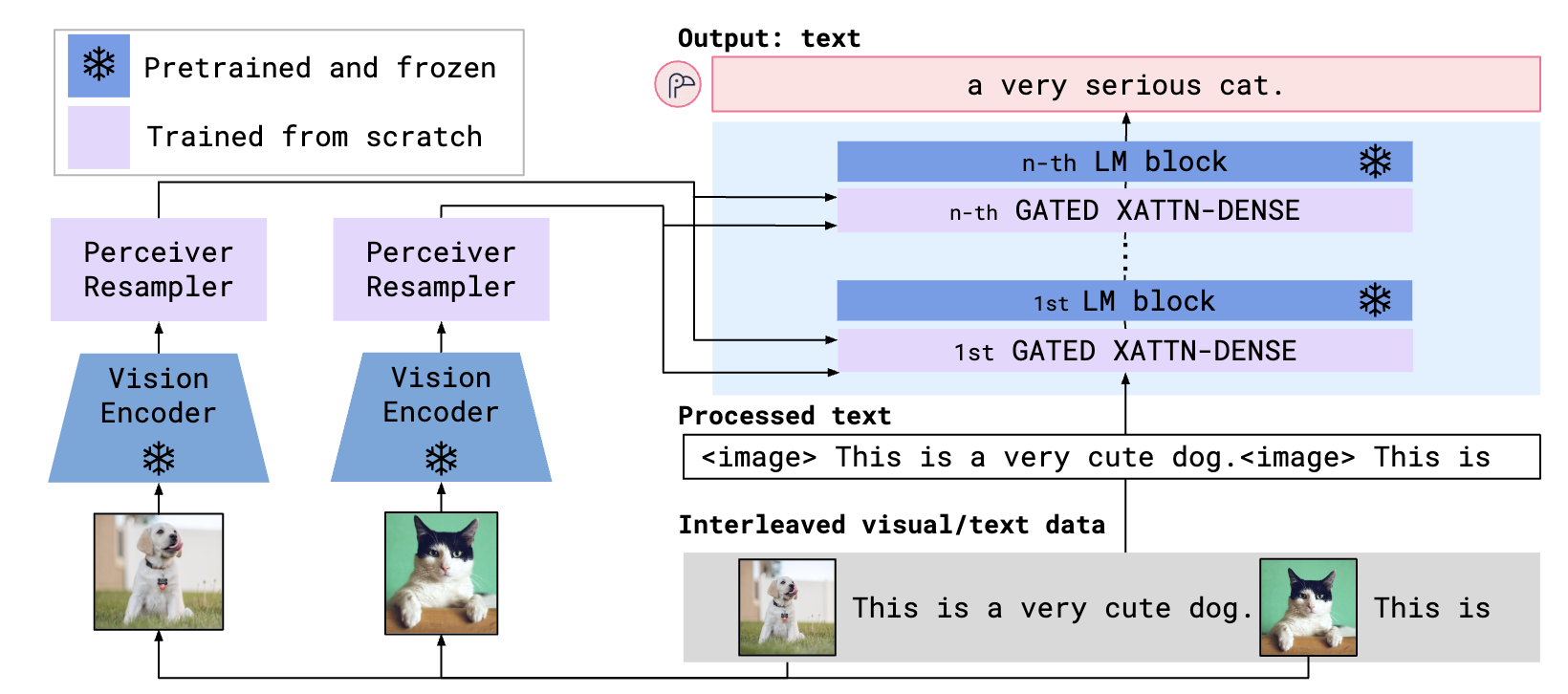
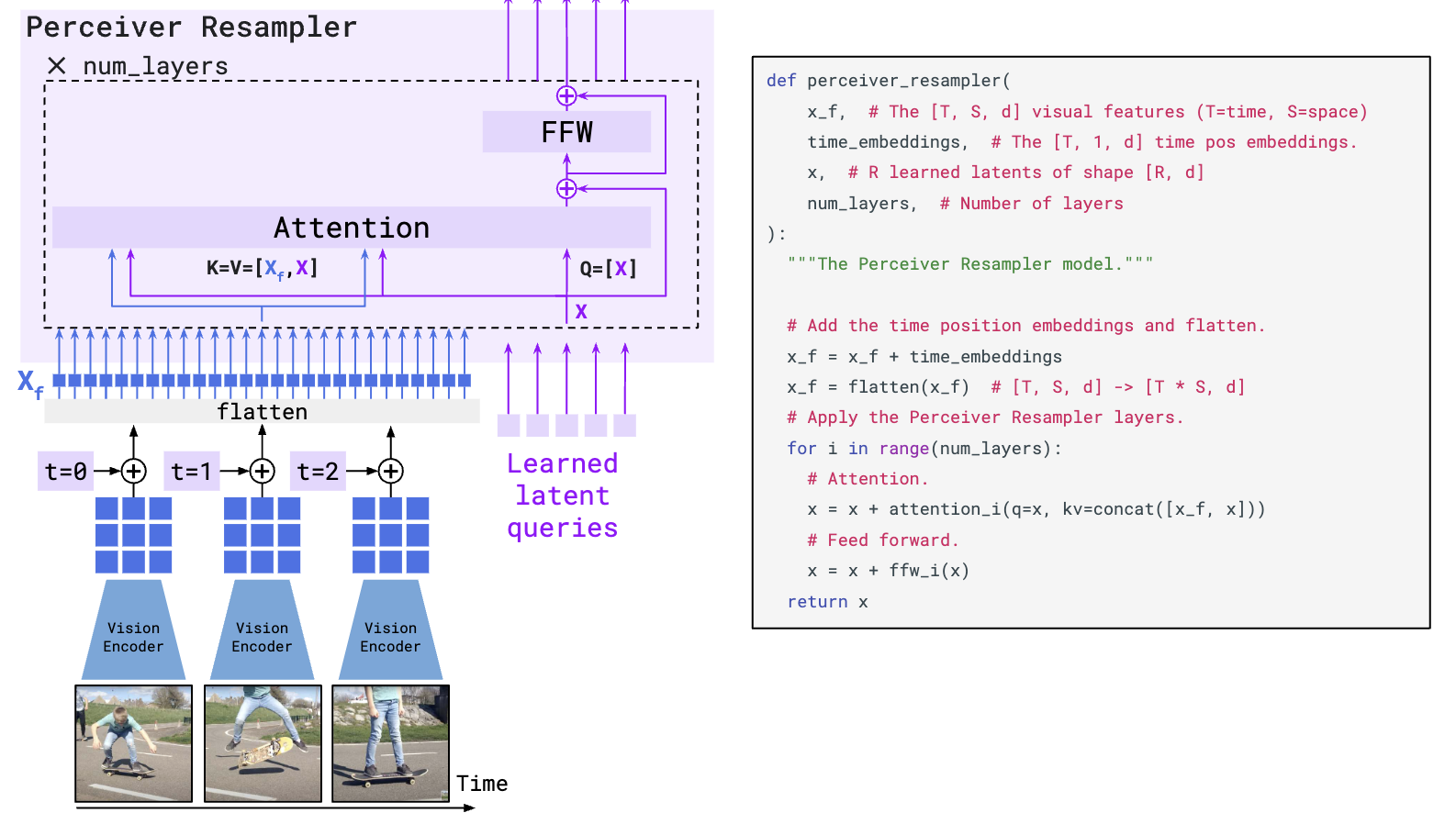
对于视觉的Encoder,使用CLIP中得到的视觉encoder提取图片特征 X_f。如下图,由于不同长度的视频和图片的特征展开后肯定是不一样长的,所以通过设计Perceiver Resampler进行重采样,以得到相同长度的特征 X。具体的做法是,通过固定长度可学习的query去和展平的视觉特征做cross attention,其中 Q=[X], K=V=[X_f,X],经过这样的几层后把query对应的这部分特征输出送到LLM就可以了。这就是视觉token的生成。
对生成的视觉token,怎么在不动LLM参数的前提下,能无缝的应用在LLM中,就需要本文提出的GATED XATTN-DENSE。如下图所示,用语言模型的输入做query,视觉token做K和V,也就是让语言模型的输入自己去选需要的视觉信息,然后将得到的特征输入到LLM中。这里有个细节需要注意,因为LLM是冻结的,所以为了保证模型初始状态不变,需要$tanh(\alpha)$层, $\alpha$是可学习的参数,初始化为0,这样随着训练的进行,视觉token就会被缓缓的加入。
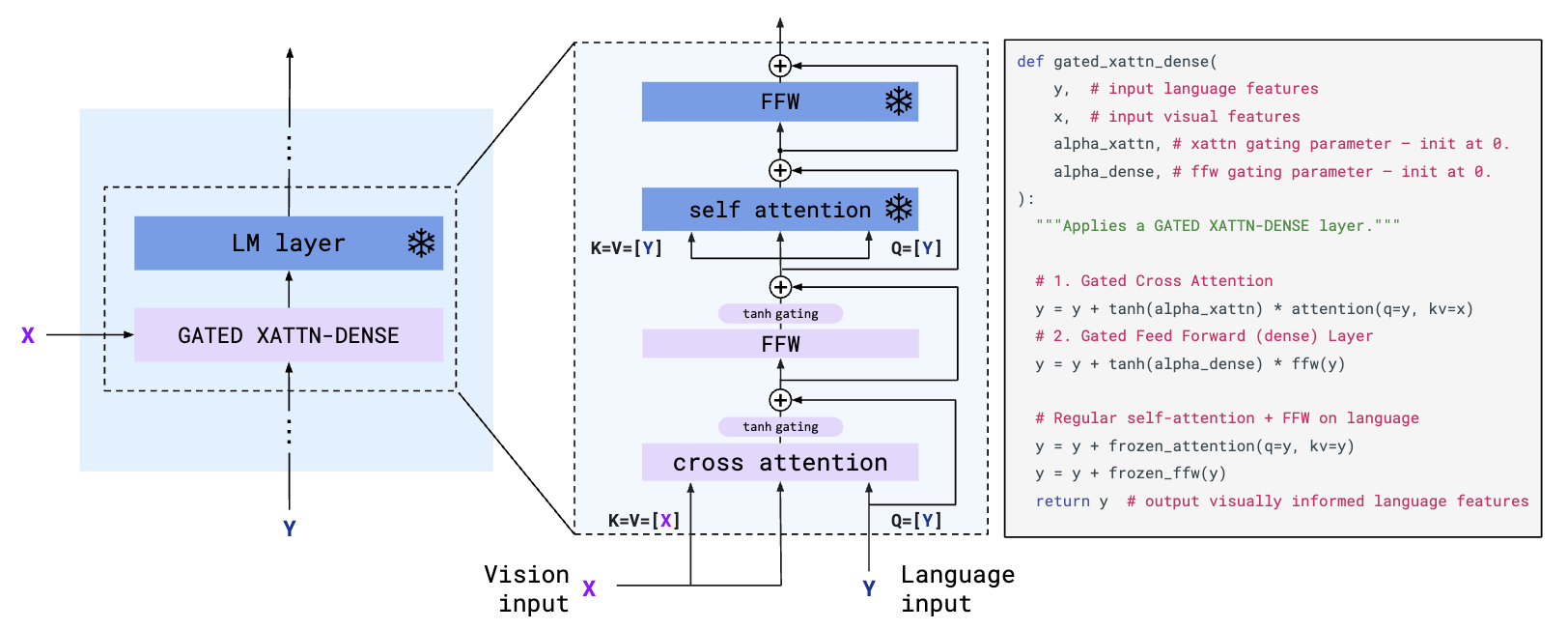
另一个实现细节是,对于多图多文字的输入,在GATED XATTN-DENSE时,文字只和对应的一个视觉token进行cross attention,其他的视觉token则通过mask来屏蔽,主要目的是不希望之前的图影响当前的结果,以及可以更好的泛化到多图输入。而且虽然视觉token只和对应的文本进行attention,但是在之后文本的self-attention中,多图的信息依然可以在这一步隐式的进行交互。
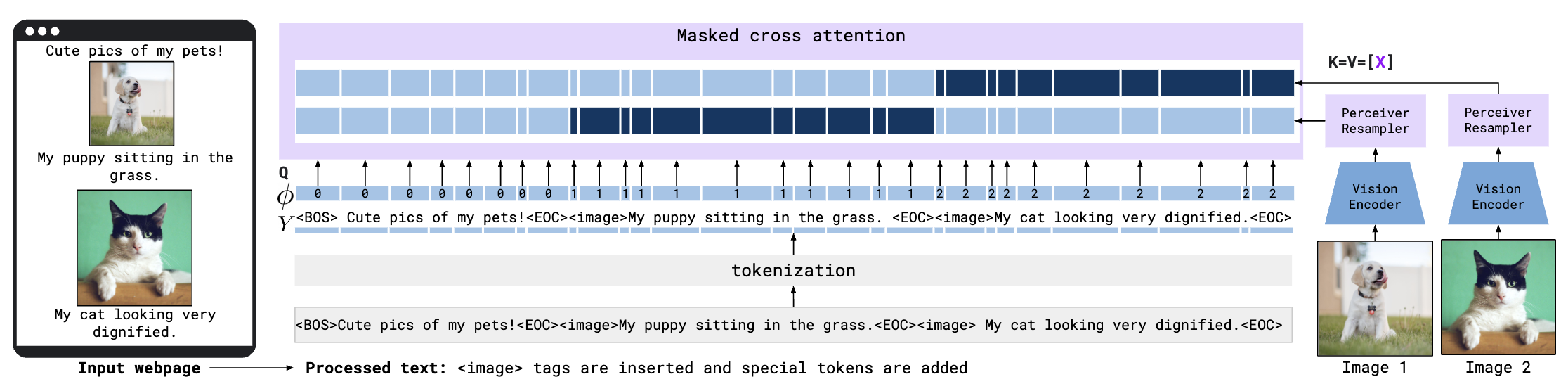
训练数据包括:
- M3W: Interleaved image and text dataset, 43M webpage
- Pairs of image/video and text: 1.8B image-text pair with alt-text, 312M image-text pairs(better and longer), 27M video pairs.
消融实验证明,在1视频+1文、1图+1文、多图多文交错三种数据中,多图多文交错是非常重要的数据。
模型根据LM大小的不同,有3B、9B、80B版本,其中80B中用的是Chinchilla 70B LM。
4. LLaVA 🌋 2023.4.17
论文:Visual Instruction Tuning(Microsoft)
(LLaVA的含义是Large Language and Vision Asistant)
造了一波丰富的QA数据,用简单的结构,达到了sota的性能。
使用ChatGPT来得到更好的数据集。具体来说,对于一张图片,我们可以提供几句Captions以及其中的Object boxes的位置,让ChatGPT生成3种形式的输出,分别是:一些一问一答的VQA、更详细的一段图片描述、结合前两者提出一些有思考性的问题和答案。论文中也给出了让ChatGPT生成VQA和详细图片描述时所使用的Prompt。
得到训练数据之后,我们看一下LLaVA的模型,他的结构非常简单,视觉Encoder使用CLIP的ViT-L/14,将图片$X_v$编码后的特征$Z_v \in \mathbb{R}^{16\times 16 \times 1024}$ 通过一个矩阵$W$投射到$H_v\in \mathbb{R}^{256 \times D}$,$D$ 的大小由所接的LLM决定。然后和文本Instruction的特征一起送入LLM即可。
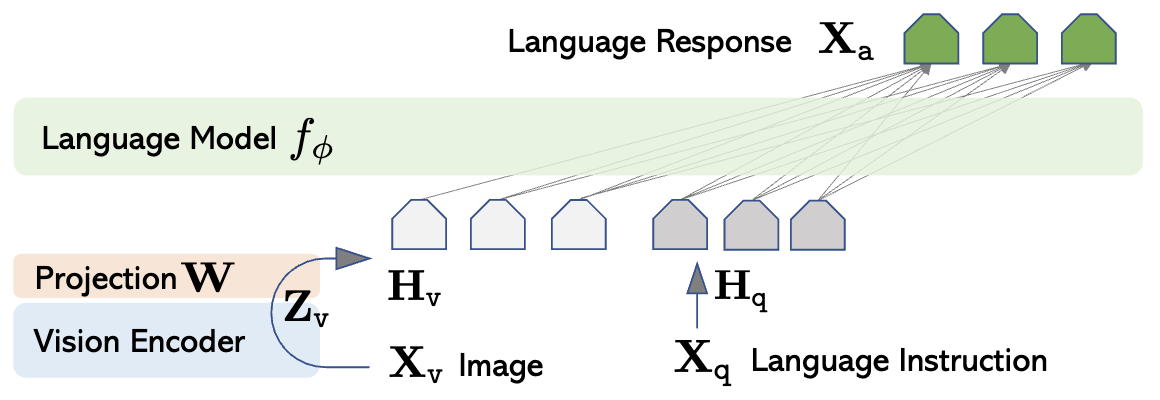
训练第一步,进行预训练:冻结Visual Encoder和LLM的参数不动,只训练$W$,让视觉token可以对齐文本的token,在这一步使用简单的Image Captions训练,输入是问题和图片$X_q\ X_v$,输出是captions,在这一步中使用了llava595k image-text pairs。第二步端到端的Finetune,训练的参数包括W和LM,而视觉Encoder不动,这一步使用了llava80k instruction-following data。
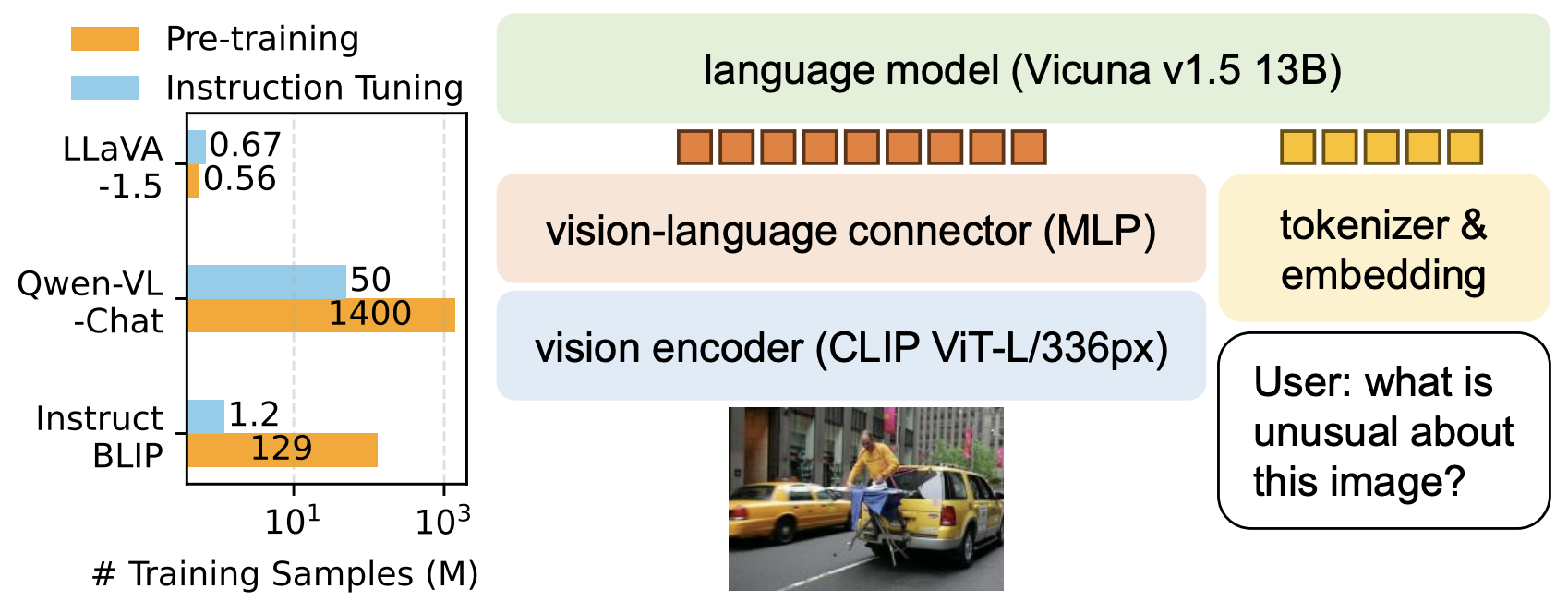
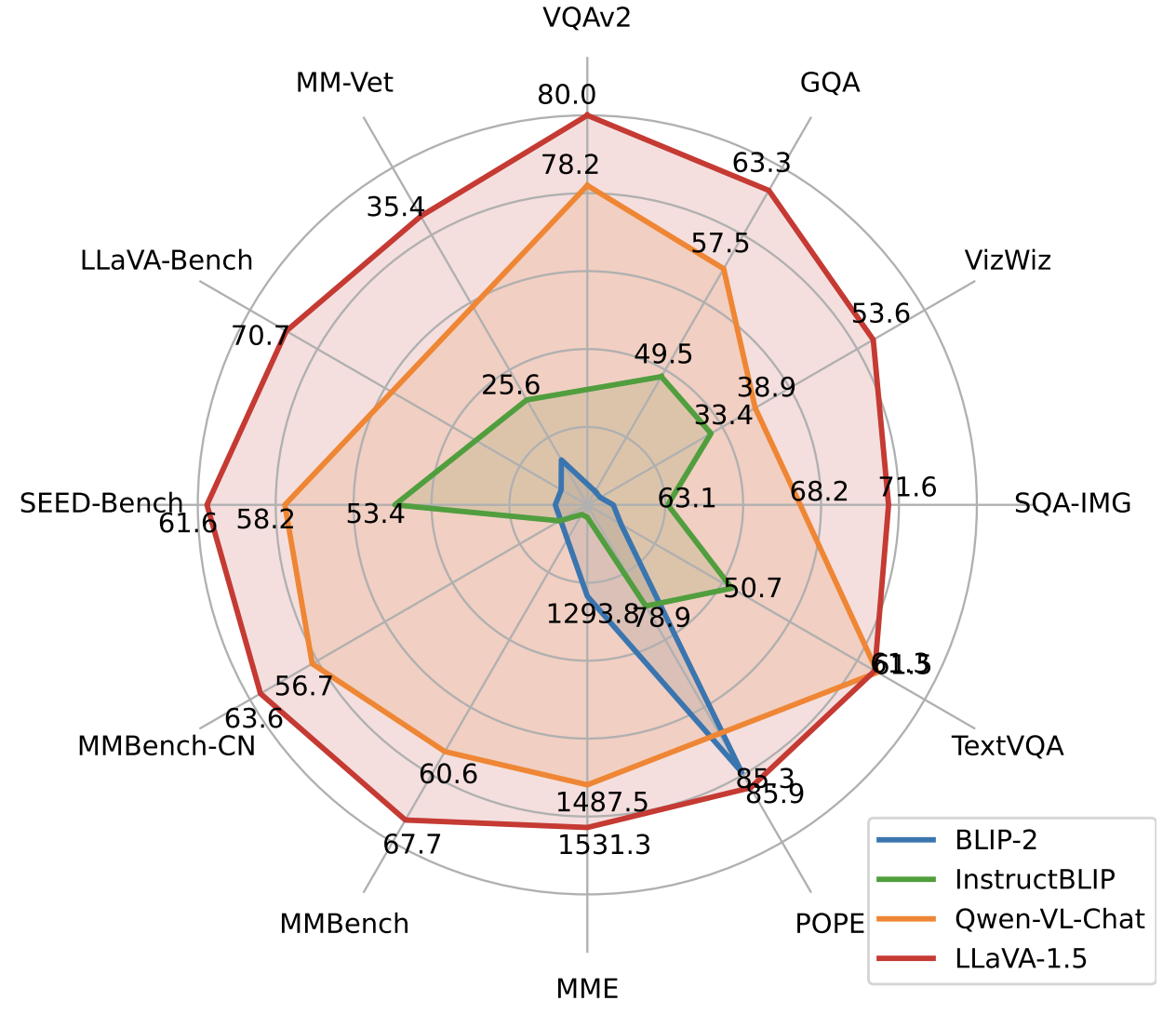
5. LLaVA-1.5 2023.10.5
论文:Improved Baselines with Visual Instruction Tuning (Microsoft)
项目地址:https://llava-vl.github.io/
demo地址:https://llava.hliu.cc/
相比 v1 的改动主要是一方面使用了更大输入分辨率的CLIP(224->336px),MLP从一层linear到2层。主要是更新了一波更优质的数据,预训练用llava558k:a subset of ∼558K image-text pairs from LAION-CC-SBU with BLIP captions, as used in LLaVA-Lightning series,sft用llava665k,组成如下图:
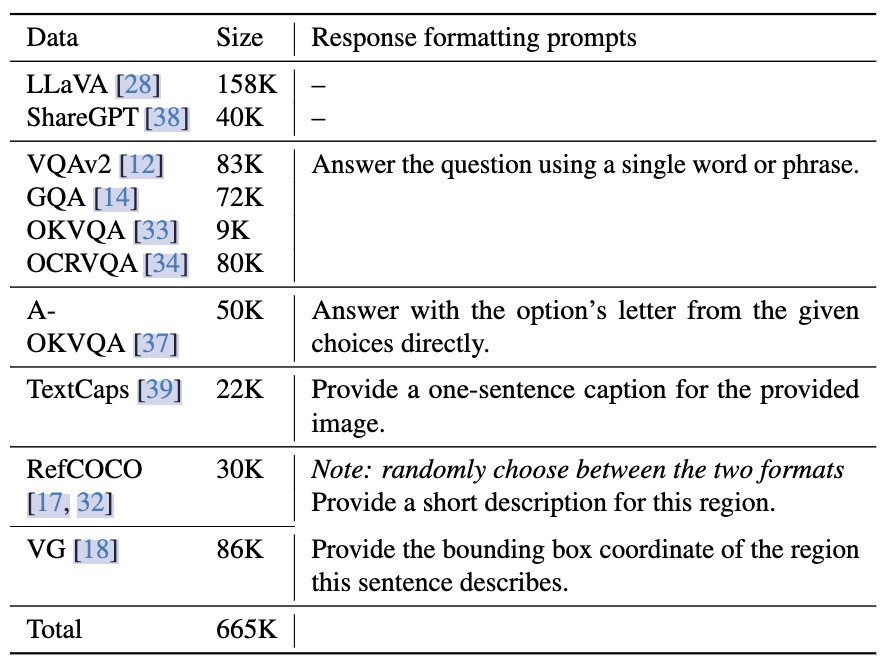
仅使用 120 万公开数据,LLaVA-1.5 在单个 8-A100 节点上用不到 1 天的时间就完成了训练。
[更新] LLaVA-1.6(也叫LLaVA-Next)2024.1.30
项目地址:https://llava-vl.github.io/blog/2024-01-30-llava-next/
数据上增加了更多高质量的sft数据,包括 LAION-GPT-V 、ShareGPT-4V 和自有回流数据,用 DocVQA 和 SynDog-EN 替换了 TextCaps(因为TextCaps和TextVQA训练数据源一样),加了图表数据 ChartQA、DVQA 和 AI2D。结构上的变动主要是采用了类似GPT4V的切图技术来提高输入分辨率,叫做 AnyRes,把输入图片切成 $\{2\times 2, 1\times \{2,3,4\}, \{2,3,4\}\times 1\}$ 中的一种,然后如下图所示输入LLM:

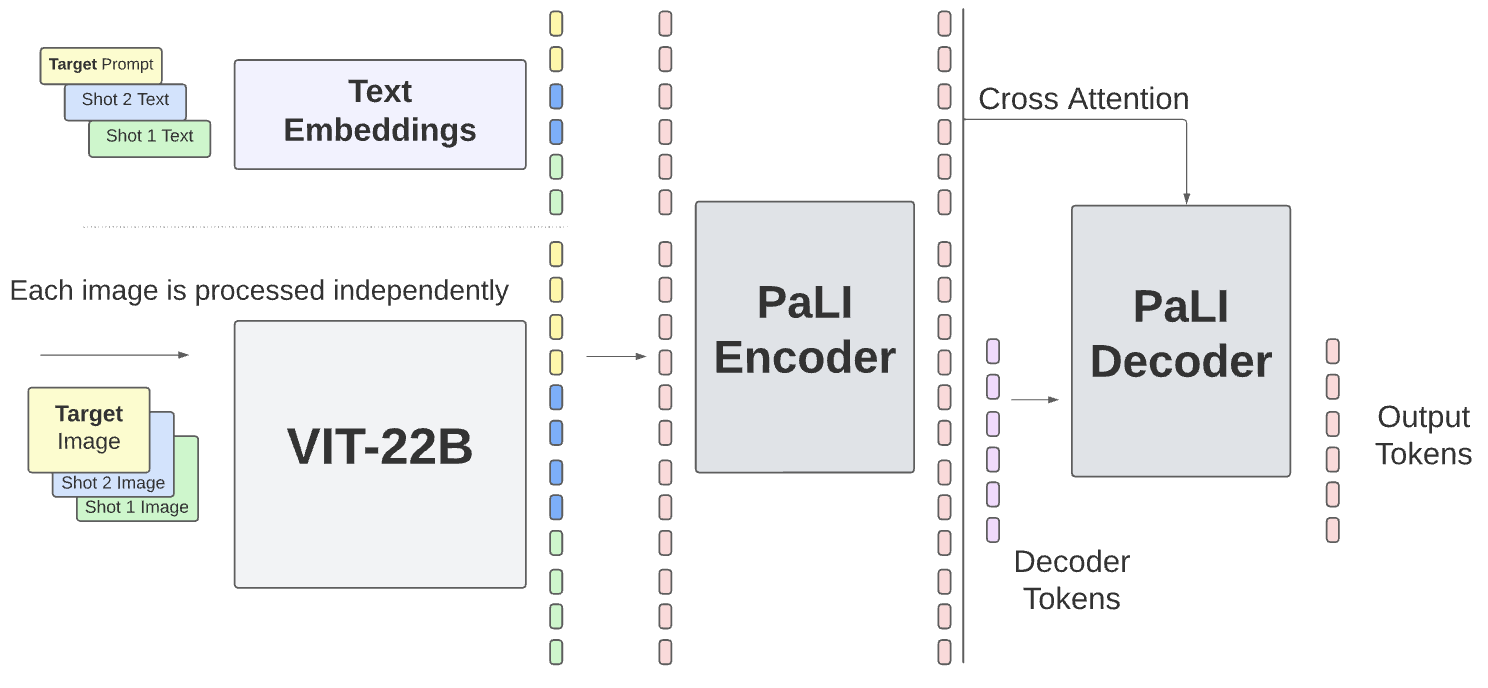
6. PaLI-X 2023.5.29
论文:PaLI-X: On Scaling up a Multilingual Vision and Language Model(Google)
(PaLI的含义是Pathways Language and Image)
这篇文章主要探索了视觉和LLM部分模型大小的Scale up,提出两个部分同时scale up可以极大提升模型性能,并在文档、图表、计数等任务上表现出涌现能力。另外也提出了用OCR数据做预训练的方法,它可以显著提升Scene-Text理解能力,体现在ST-VQA、TextVQA,对常规的VQAv2也有提点儿作用。
视觉Encoder使用ViT-22B,对于多图输入,将各个图经过Encoder得到的特征concate起来。没有使用flamingo中的多图mask,本文消融说加mask会掉2个点。语言模型使用了32B的UL2(encoder-decoder架构)。训练分2个阶段,第一阶段冻住vit,打开其他,分辨率为224;第二阶段finetune,也是冻住vit,finetune的数据分了好几个子阶段来训,分辨率分别是448,672,756慢慢变大。
7. Donut 🍩 2022.10.6
论文:OCR-free Document Understanding Transformer(NAVER)
(Donut的含义是Document understanding transformer)
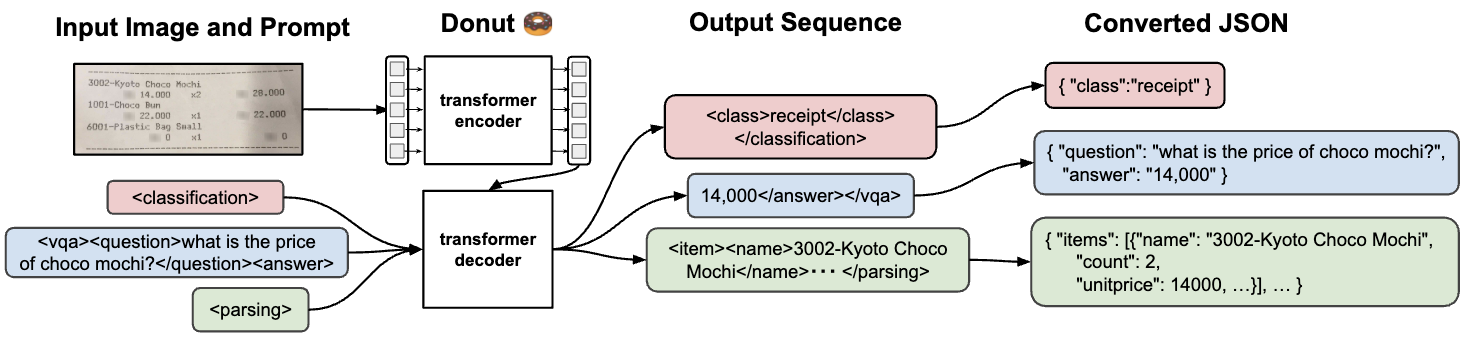
识别图片中的文字,转化成json格式。训练损失为交叉墒损失。在预训练阶段,使用有11M图片的IIT-CDIP数据集和自己构建的SynthDoG生成数据,生成数据为4个语言各生成0.5M样本。在finetune阶段,将下游任务如文档分类、信息提取、VQA变为json预测问题。
预训练阶段的图像分辨率为2560×1920。decoder最大长度为1536。
8. Nougat 2023.8.25
论文:Nougat: Neural Optical Understanding for Academic Documents(Meta)
项目地址:https://github.com/facebookresearch/nougat
(Nougat的含义是 Neural Optical Understanding for Academic Documents)
本文工作提出一个OCR神器,可以识别pdf中的文字、数学公式、表格,并转换成markdown格式的文本。
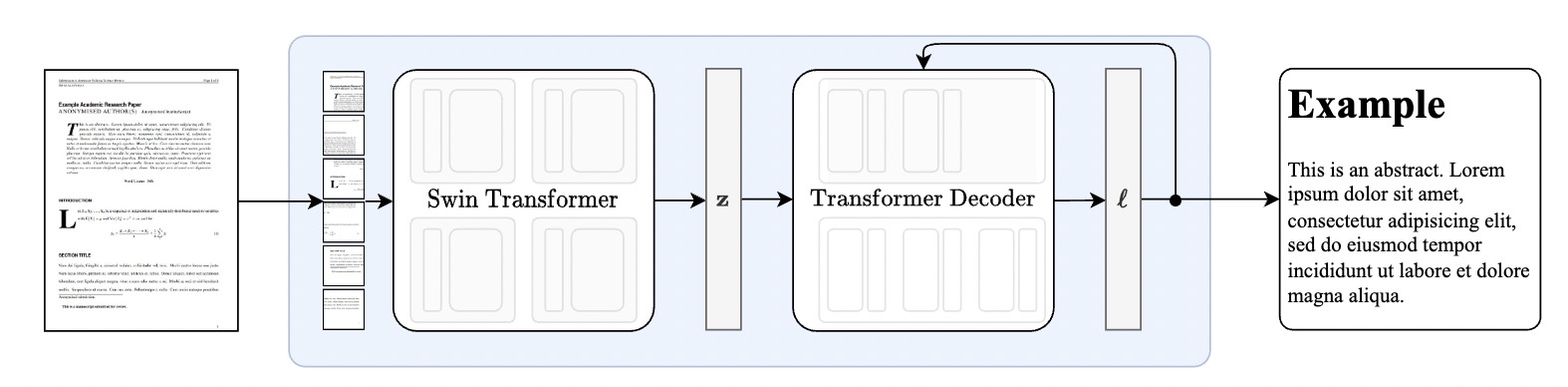
模型结构和Donut完全相同。视觉encoder首先接受一张文档图像,A4文档用96 DPI渲染,裁剪边距并 resize and pad 到(H,W)=(896,672)以适应swin-transformer。我们使用了Swin Transformer作为视觉Encoder,Swin Transformer将图像分为不重叠的固定大小的窗口,然后应用一系列的自注意力层来聚集跨窗口的信息。该模型输出一个embedding patch $Z \in \mathbb{R}^{d \times N}$,d是embedding的维度,N是Swin切图的patch的数量。使用decoder-only transformer结构的 mBART解码器解码Z,然后生成一系列tokens,最后tokens被投影到vocabulary的大小,产生logits,词表大小设为S = 4096。模型总大小为350M。
训练数据是从arXiv、PMC以及IDL三种渠道获取的文章处理而来的,共计8,204,754页,其中大部分是arXiv。本工作也给出了这个自动和无监督的数据集生成过程。
9. Kosmos 2023.3.1
论文:Language Is Not All You Need: Aligning Perception with Language Models(Microsoft)
10. Shikra 2023.7.3
论文:Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic(商汤)
项目地址:https://github.com/shikras/shikra
在人类的日常交流中,经常会关注场景中的不同区域或物体,双方都可以通过说话并指向这些区域来进行高效的信息交换。我们将这种对话模式称为参考对话(Referential Dialogue)。本文通过对LLaVA-13B进行Chessboard Test证明现有的MLLM没有对精确位置的感知能力,所谓Chessboard Test就是问模型某某类别物体在图片的左上、右上、左下、还是右下。而 Shikra 模型就有参考对话的能力,既可以理解位置输入,也可以产生位置输出,位置用点或框表示。
Shikra的模型结构类似于LLaVA,使用MLP连接图像和语言Embedding。它直接在文本的任意位置插入$[x_{min}, y_{min}, x_{max}, y_{max}]$或$[x_{center}, y_{center}]$代表框和点,位置需要经过归一化并统一保留三位小数。作者实验证明这种方式相比于扩充特定的位置词表效果更好,虽然会以占用较多的token数为代价。
Shikra分两个阶段训练,两个阶段用到的数据不同。这两个阶段都是冻结visual encoder,训练 MLP和LLM。Shikra处理不同的任务有不同的prompt模板,为了在推理时模型能理解各种各样的表达,在训练时每个任务的prompt由GPT4重写了几百个,训练时对其随机采样。Shikra训练还使用了CoT,本文还指出,相比不使用或使用普通的思维链,使用带有位置的思维链即 $Q \rightarrow C^{Point}A$ 对QA结果有很大提升。
Shikra只适用于英文;不适用于密集物体的检测和分割。
11. ChatSpot 2023.7.18
论文:ChatSpot: Bootstrapping Multimodal LLMs via Precise Referring Instruction Tuning(旷视)
项目地址:https://github.com/Ahnsun/ChatSpot
ChatSpot支持点和框的输入进行推理,不支持点和框的输出。ChatSpot提出用两种类型的数据,第一种是Image-level Instructions,例如Given an image <image>. Describe the whole image in detail或者Given an image <image>, please tell me: <question>。第二种是Region-level Instructions,例如Given an image <image>, What is the object doing in the region? <region>,其中<region> = <box>Φ(Rt)</box>, Φ(Rt)是所选区域内的一些点的xy坐标,归一化到$[0,1]$范围,变为text token。
ChatSpot的模型结构和训练方法类似于LLaVA,使用MLP连接图像和语言Embedding,在第一步预训练时,冻结Visual Encoder和LLM,第一步主要使用image-text instruction-following data训练。在第二步finetune时,只冻结Visual Encoder,这一步主要使用region-text instruction-following data训练。
12. Emu 2023.7.11
论文:Generative Pretraining in Multimodality(北京智源)
项目地址:https://github.com/baaivision/Emu
Emu可以处理交错的(interleaved)图像/视频、文本作为输入,并输出文本或图像。可以完成的zero-shot/few-shot任务包括:image captioning, visual question answering, video question answering and text-to-image generation。这些任务的例子展示如下图所示。其中image captioning, visual question answering, and interleaved multi-image understanding 任务使用instruction-tuned model;in-context learning任务使用预训练模型;image blending, text-to-image 和 in-context generation任务使用了图像生成模型。

Emu的网络结构如下图,它包括Visual Encoder(EVA-CLIP), Causal Transformer, Multimodal Modeling(LLaMA-13B), and Visual Decoder(Stable Diffusion)四部分,分别用括号中的模型初始化。其中图片的输入会resize到224×224。Emu在预训练阶段是自监督的,预训练时的目标是,统一以自回归的方式classify the next text token or regress the next visual embedding,计算文本生成损失和图片生成损失,文本用交叉墒损失,图片用l2损失。但是对于图片来说,自回归的不是2D原图,因为原始图片不像文本一样具有从左到右的因果关系,所以他们把过CLIP后的图像编码即dense visual feature输入causal transformer,输出N个tokens来捕获图片中的因果关系,即 把没有因果的2D信号转化为有因果关系的1D序列信号。图片部分自回归的就是这个1D tokens。Causal Transformer的结构类似于transformer的decoder部分,由self-attention、cross-attention、FFN组成。
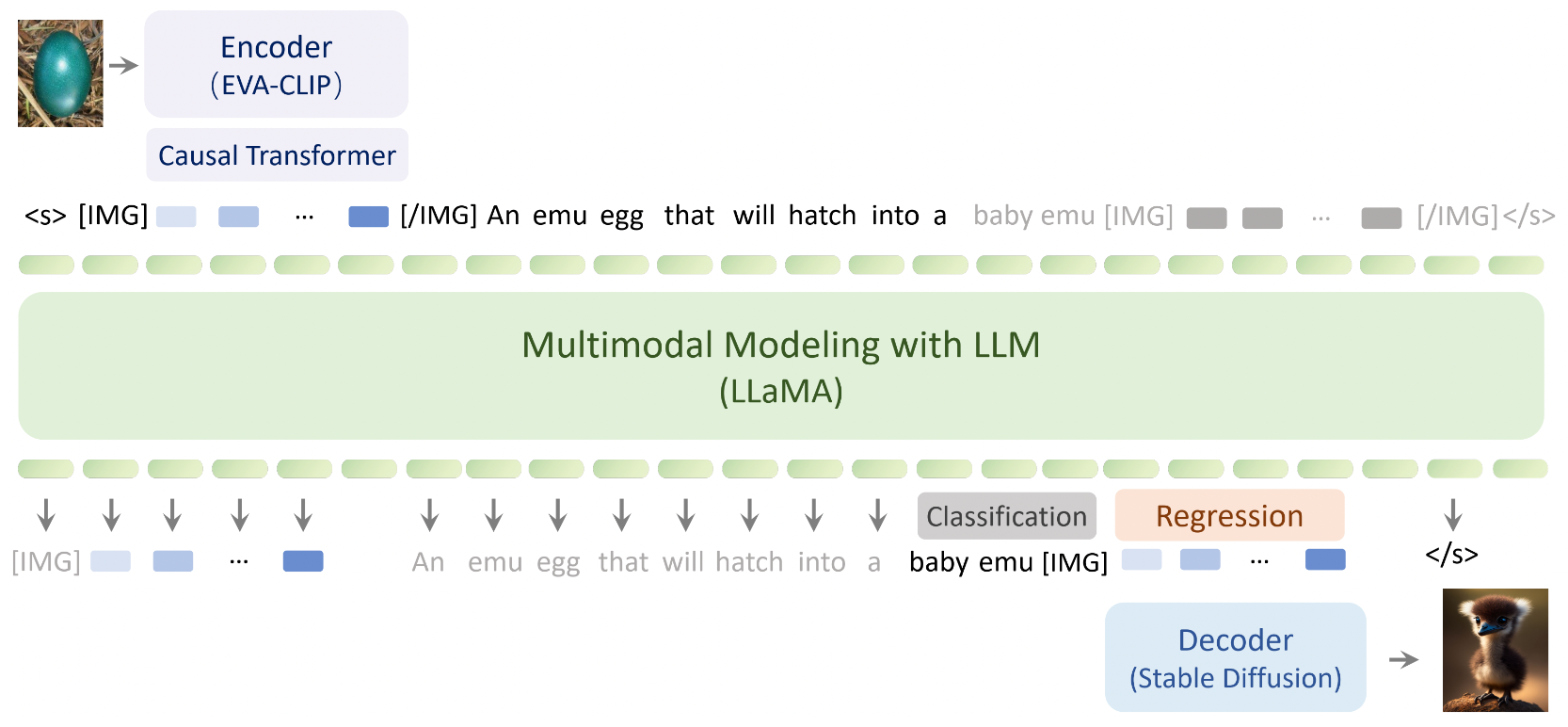
在instruction tuning阶段是有监督的,所有数据以这样的模版格式封装:<System Message> [USER]: <Instruction> [ASSISTANT]: <Answer>。只有<Answer>部分会计算损失。
Emu的性能强于Kosmos和Flamingo。
13. DreamLLM 2023.9.20
论文:[https://arxiv.org/abs/2309.11499](DreamLLM: Synergistic Multimodal Comprehension and Creation) (西交&旷视)
主页:https://dreamllm.github.io/
14. NExT-Chat 2023.11.19
Github:https://github.com/NExT-ChatV/NExT-Chat
知乎:NExT-Chat:可以对话、检测、分割的多模态大模型
15. Vary 2023.10
论文:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models (ECCV 2024)
上面的VLM都是基于CLIP做Vision Encoder的,然而我们发现CLIP存在一些问题:
- 对于图片中的外语,存在out-of-vocabulary问题
- CLIP更关注图片级的视觉信息,而对细粒度的信息存在压缩损失
对此,Vary对Vision Encoder进行了研究,并提出一套“扩充视觉词表”的方法框架。详细见:Vary—提升LVLM的dense和细粒度视觉感知能力
以最能反应上述问题的dense OCR任务为例,Vary首次实现了端到端的中英文OCR,与传统pipeline相比,模型维护成本更低,精度上限更高。
16. OneChart
论文:OneChart: Purify the Chart Structural Extraction via One Auxiliary Token(ACMMM 2024)
详细见:OneChart—让VLM知之为知之,不知为不知

