VLM常见Dataset和Benchmark
本文对VLM领域多个任务的常见数据集和benchmark做了简要介绍,以方便读友看论文时参考。
⚠️注意:本文信息仍在时常更新中
常见任务和评测数据
常见的多模态任务有:视觉问答VQA、视觉常识推理VCR(选择题并解释原因)、指代表达RE(给定图片和一个句子,判断句子正确还是错误)、图文检索VLR(根据文字检索图片)。生成图片类任务有:图像样式转移、文本驱动的图像生成等。
不同任务常用benchmark如下:
VLM benchmark:
- MM-Vet
- MMBench
- MMBench-CN
- SEED-Bench
- LLaVA-Bench
- MME
- 测幻觉:POPE
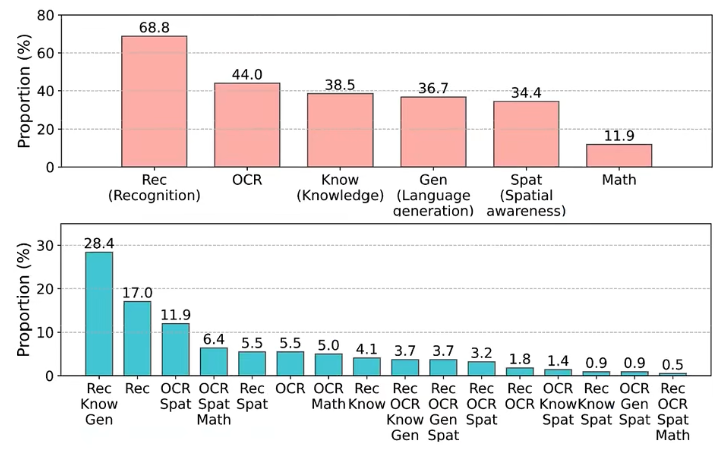
其中MM-Vet归纳了VLM需要具备的6种能力,并组合出16种任务,比例如下:
幻觉
-
Object HalBench
$$\text{CHAIR}_{I} = \frac{\lvert \{\text{hallucinated objects}\} \rvert}{\lvert \{\text{all mentioned objects}\} \rvert}, \text{CHAIR}_{S} = \frac{\lvert \{\text{captions with hallucinated objects}\} \rvert}{\lvert \{\text{all captions}\} \rvert}$$ -
MHuman Eval
- Hallucination frequency
-
MMHal-Bench
- Info: GPT-4 evaluated score
- Hallucination frequency
Image Caption
- COCO
- MM-IT-Cap
Visual Question Answering(VQA)
- VQAv2
- VizWiz
- GQA (自然场景图问答,有框标柱)
- Hateful Meme
- PointQA(ChatSpot)
- COCO Text(ChatSpot)
- OKVQA
- TextVQA
图片来源 OpenImages v3
训练集:21,953 张图像,34,602 个问题,验证集: 3,166 张图像, 5,000 个问题
测试集: 3,289 张图像, 5,734 个问题 - STVQA
数据来源 :Coco-Text, Visal Genome, VizWiz, ICDAR(13+15), ImageNet, IIIT-STR
训练集:19,027张图像,26,308个问题
测试集: 2,993 张图像, 4,163个问题 - DocVQA
- OCR-VQA
207572 张图像(书的封面),超过100万个问答对 ( train : val : test = 8 : 1 : 1 )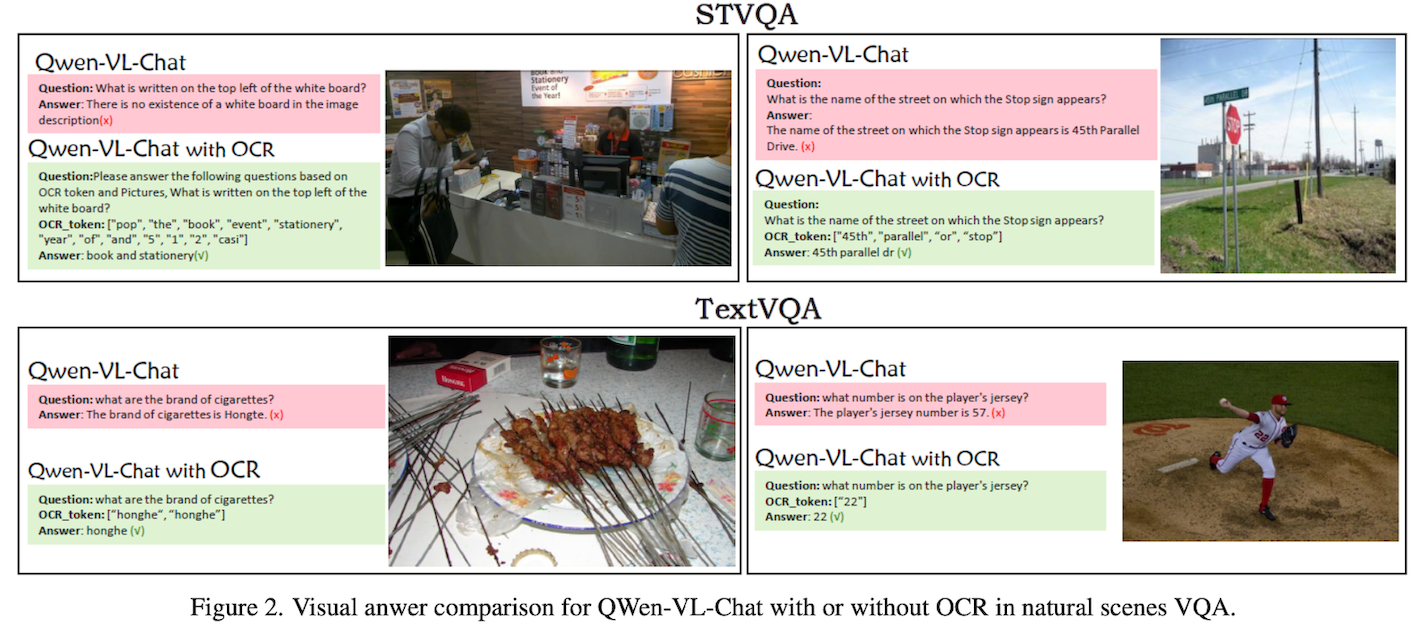

日常场景的那种OCR开源数据,来源是20个公开数据集,约5.6M真实的+17.9M仿真的:
https://github.com/large-ocr-model/large-ocr-model.github.io/blob/main/Data.md
SynthDoG datasets: Donut提出的数据集,用于增强ocr

The links to the SynthDoG-generated datasets are here:
synthdog-en: English, 0.5M.
synthdog-zh: Chinese, 0.5M.
synthdog-ja: Japanese, 0.5M.
synthdog-ko: Korean, 0.5M.
- ChartQA:test有1509张图
- PlotQA:test有33657张图
- DVQA
视频QA
- STAR
Visual Grounding/REC
- Flickr30k(短语定位)
- RefCOCO、
- RefCOCO+、
- RefCOCOg:
是三个从MSCOCO中选取图像和参考对象的Visual Grounding数据集。目标属于80个目标类。
RefCOCO有19,994幅图像,包含142,210个引用表达式,包含50,000个对象实例。
RefCOCO+共有19,992幅图像,包含49,856个对象实例的141,564个引用表达式。
RefCOCOg有25,799幅图像,指称表达式95,010个,对象实例49,822个。
在RefCOCO和RefCOCO+上,遵循train / val / test A / test B的拆分,testA中的图像包含多人,testB中的图像包含所有其他对象。RefCOCOg遵循train / val / test 的拆分。
RefCOCO的表达式分别为120,624 / 10,834 / 5,657 / 5,095; 框的数量分别为42,404 / 3,811 / 1,975 / 1,810
RefCOCO+的表达式分别为120,191 / 10,758 / 5,726 / 4,889; 框的数量分别为42,278 / 3,805 / 1,975 / 1,798
RefCOCOg的表达式分别为80,512 / 4,896 / 9,602; 框的数量分别为42,226 / 2,573 / 5,023
RefCOCO的查询包括方位或属性,如“中间的人”,“左边 红衣服”,“蓝车”;RefCOCO+的查询不包含方位,如“手里拿着球拍”;RefCOCOg的查询长度普遍大于RefCOCO和RefCOCO+:RefCOCO、RefCOCO+、RefCOCOg的平均长度分别为3.61、3.53、8.43。
RES
- PhraseCut
- RefCOCO
Detection
- COCO,train和val有标注
COCO2014: train包括 82783张图,val包括 40504张图,test包括40775张图
COCO2017: train包括 118287张图,val包括 5000张图,test包括 40670张图 - Object365
- OpenImage
常见VLM训练数据
图文对数据
LAION2B:LAION5B数据集是从网页数据Common Crawl中筛选出来的图像-文本对数据集,它包含5.85B的图像-文本对,其中文本为英文的数据量为2.32B,这就是LAION2B数据集,它是LAION5B的英文子集。著名的stable diffusion generative model训练集就包括了LAION5B。
LAION-400M:下载原图和文本对的话,大概有10T左右。LAION-400M提供了400M数量的图文对,以及他们的CLIP embedding和kNN索引,因此可以对这个大数据集高效索引。索引网站:https://rom1504.github.io/clip-retrieval/
LAION-400M在收集数据时,做了一些过滤设定:
- 将文本短于5个字母或者图像小于5kb的图文对丢弃;
- 去重操作;
- 用CLIP计算图文相似性,抛弃掉相似性低于0.3的图文对;(很重要)
- 筛除一些不合法的图文对,比如adult/violence/insulting等等。(love and peace化)
LAION COCO: 对LAION2B中的600M 个图片,使用 BLIP L/14 and 2 CLIP versions (L/14 and RN50x64)打了COCO风格的captions标注。数据官网:LAION COCO
DataComp-1B:Apple公司训练他们的CLIP使用的数据。
TaiSu(太素): 中文视觉语言预训练数据集,数据量 166M。数据官网:TaiSu
COYO:由于伴随的文本取自Alt-text,COYO的文本通常很短。
LAION-GPT-4V:12.4k,LLaVA-1.6用了此数据。
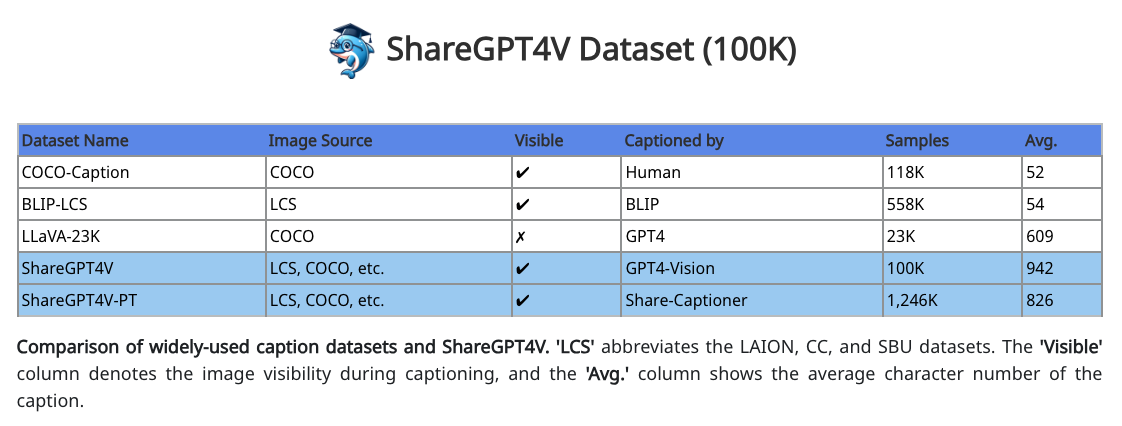
ShareGPT4V: 100k个GPT4V生成的caption图文对,基于这数据训了个caption模型并开源,并给了1.2M个他们模型生成的高质量caption图文对。LLaVA-1.6用了此数据。
interleave数据
在论文VILA: On Pre-training for Visual Language Models中指出,pretrain阶段需要加interleave数据。最好是interleave和pair都用。
SFT阶段需要加text数据,可以把pretrain阶段 MMLU 的掉点救回来。
| Dataset | Type | Text Src. | #img/sample | #tok./img |
|---|---|---|---|---|
| MMC4 | Interleave | HTML | 4.0 | 122.5 |
| COYO | Img-text pair | Alt-text | 1 | 22.7 |
MMC4:Github论文包含了 585M 张图片和 43B 个英文单词,这些图片和文字相互交织,已经过滤了NSFW图像、广告等。它是对流行的纯文本c4语料库的扩充,其中包含了图像交错。mmc4涵盖了日常话题,如烹饪、旅行、技术等。
M3W (Multi Modal Massive Web):Flamingo使用的数据,没开源,是作者们从网页挖一些带有文本和图像的数据、视频、以及用了别人的文本和图像pair的数据,用185M图像和182G的文本,构成M3W数据集。

SparklesDialogue:Github
视频数据
WebVid-10M:论文 视频caption数据,一共有10M的video clip,还有个2.5M的子集。

HowTo-100M:HowTo100M 是一个大型叙述视频数据集,重点是教学视频,其中内容创建者教授复杂的任务,并明确解释屏幕上的视觉内容。 HowTo100M 共有以下功能:
- 1.36 亿个视频剪辑,其字幕来自 120 万个 YouTube 视频(15 年的视频)
- 烹饪、手工制作、个人护理、园艺或健身等领域的 23k 项活动
每个视频都配有一个旁白,可从 Youtube 自动下载字幕。


