目标检测-FCOS-ICCV2019
这篇文章是我入门目标检测接触的第一篇论文,也是我本科毕设的baseline,因此文章中可能有很多看起来很幼稚的问题,感谢师兄当时的耐心!
(红色字为问题,绿色框为批注答疑,高亮为当时没理解清楚以后需留意补充的内容。)
论文:FCOS: Fully Convolutional One-Stage Object Detection
代码:https://github.com/tianzhi0549/FCOS
FCOS算法详解(全文写的非常好,就不搬运了):https://blog.csdn.net/WZZ18191171661/article/details/89258086
FCOS=backbone+FPN+分类/回归/centerness
感觉最创新的就是centerness,然后feature map的表示也值得注意一下
感觉anchor-free和anchor-based的区别并不大,FCOS可以看做feature map的每个点有一个anchor,大小就是1x1。anchor-based的方法相当于列举了几个例子然后回归微调,而anchor-free是直接进行一个大的回归。所以,anchor-free算法的好坏或许一个原因是取决于回归方法?
- 背景
Anchor-based检测器对anchor的大小、纵横比、数量这些超参数敏感。由于anchor固定,所以对形状变化大的物体(特别是小物体)表现差,对新的检测任务需要重新设计。大量的anchor造成训练时正负样本不均衡问题。大量anchor和ground-truth计算IoU加大了计算量。
现有的Anchor-free检测器有YOLOv1,CornerNet,DenseBox。Anchor-free面临的常见困难是:特征图上的点与GT框(实际标注框)匹配时,一个特征点可能同时落在多个GT框中,即ambiguity。
- Architecture
backbone是ResNet-50。使用FPN,将不同大小规模的物体利用公式(详见上述FPN)分入不同的feature map,极大的减少了边框覆盖的几率。在feature_map的每个位置进行分类、回归和centerness操作,进行网络训练获取网络模型,其中5个Head是参数共享的。
预测时,输入图片经过前向传播,得到feature map每个位置的分类得分$p_{x,y}$和回归预测$t_{x,y}$,选取$p_{x,y}>0.05$的作为positive samples应用回归转换公式,得到最后的预测BBox。把五个Head的结果综合在一起,经过NMS等后处理操作得到最终结果(NMS中使用的排序score为 classification score 和 center-ness score 的乘积)。
FCOS结构图如下,其中P6和P7非整除,以P7为例,映射回原图有较大误差0.75x128=96
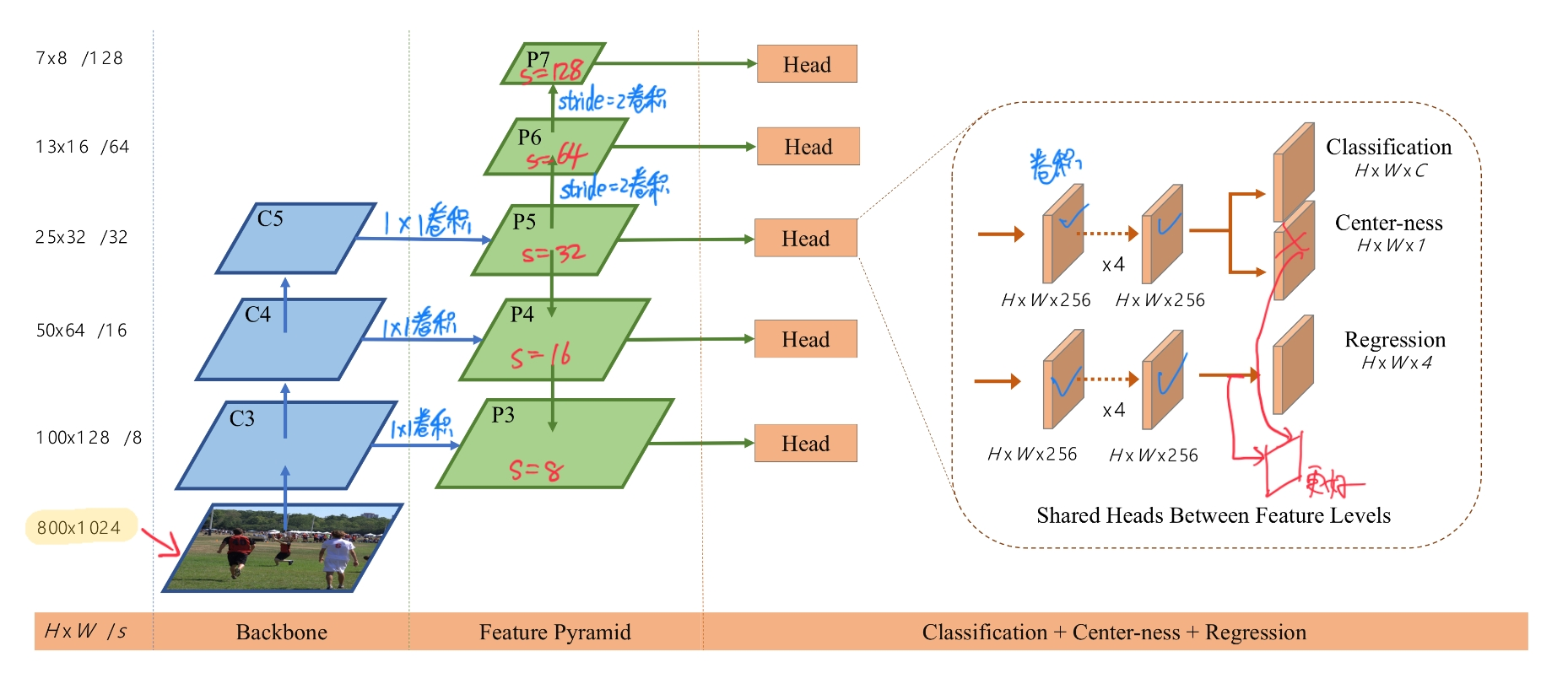
Q:这里Head进行分类的是feature map的每个点吗?能否先进行回归,然后再将回归后的框分类呢?
A:把特征图每个点(l,t,r,b)对应的部分依次分类,有ROIPooling这类的操作的
至于先回归后在框里做分类,这样会使网络增加很多双检测器里的操作(roialign这类的)这样有点类似于级连检测器的操作cascadercnn,也有点类似于refinedet,但单阶段检测器前期预测不稳定时基于错误的回归框内特征对分类分支进行训练可能会导致网络无法有效收敛。后一个问题也可以通过实验验证下,这一点是我个人看法,可能会跟实际情况有误。
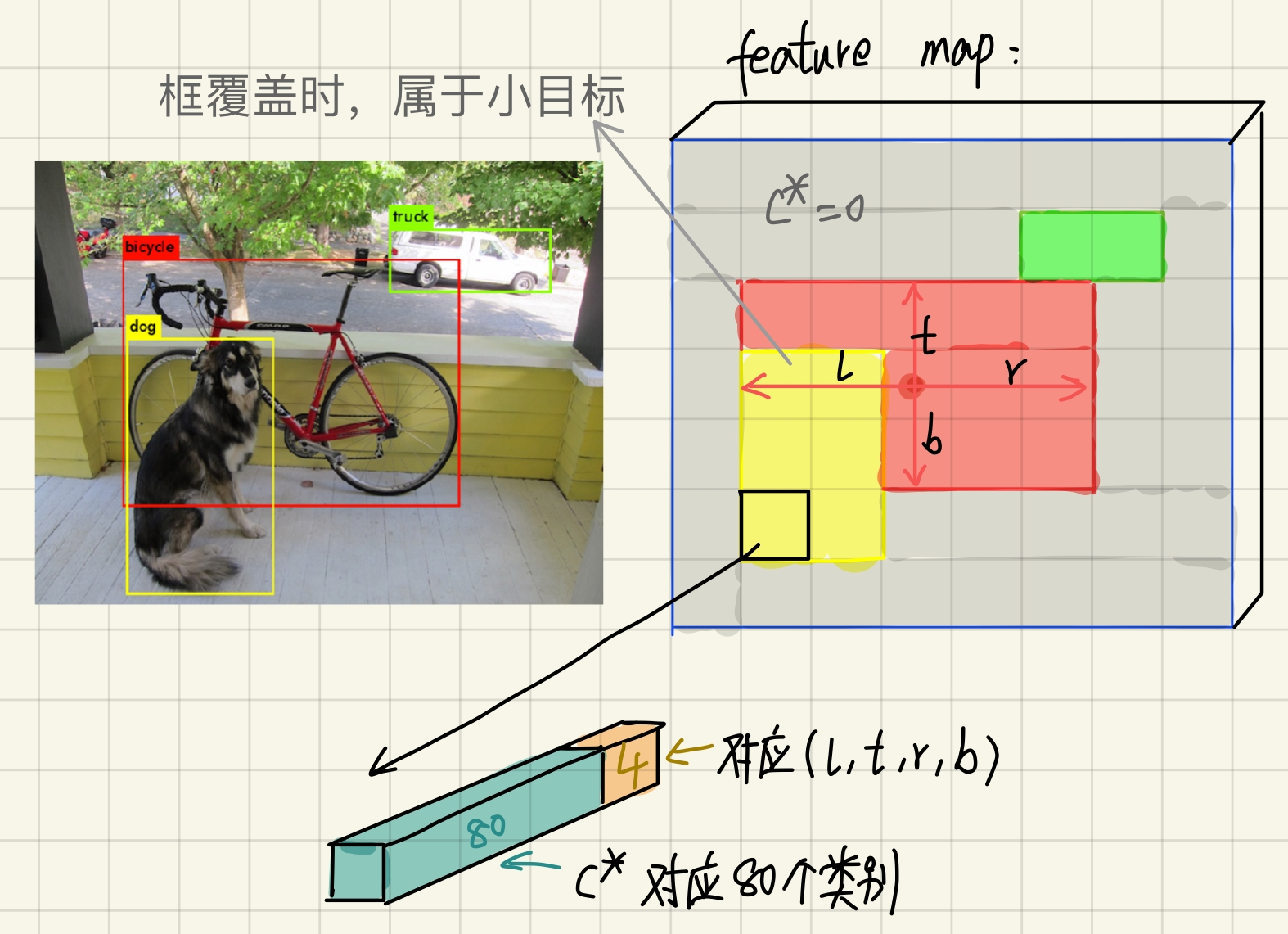
feature map及label方法图示如下,详见下方具体细节1
在YOLOv1中,将输入图片切分成grid/cell,只有物体中心的一个grid记作positive(而非包含这个物体的所有gird),即YOLOv1仅预测物体中心附近的bounding box,召回率低。而在FOS中,把所有包含物体的地方都记作positive。
康hk Q:能不能将(l, t, r, b)四维的回归改成(l, t, r, b, ϴ)五维的回归,其中 ϴ 表示角度
闫jq师兄 A:可以,这种情况通常是进行有方向倾斜框检测时必须添加的一个变量
康hk Q:假如有 C 类类别,分类器是用 C 类多类分类器还是采用 C 个二元分类器?两者有什么
区别?闫jq师兄 A:一般是使用C+1类(加一个背景类)多类分类器或C个二元分类器。C+1类多类分类器通常使用softmax层实现,因此相同对象不同类别之间是存在对抗关系的(概率总和为1)。而C个而分类器针对每个类别都会进行是或不是的判别,允许存在多个类别的置信度都比较高的情况(通常这类分类器应用于类别存在重叠的分类场景下,在这类数据集下,物体可能会具有多个标签:如一张哈士奇狗的图像可以具有犬类,哈士奇犬的标签。)而具体代码实现中使用到了focal loss进行分类损失的计算,在这类情况下,现有代码大多使用的是C个二元分类器(部分版本代码只实现了这一情况下的focal loss损失计算)。
损失函数:
$$
\begin{aligned}
L\left(\left\{\boldsymbol{p}_{x, y}\right\},\left\{\boldsymbol{t}_{x, y}\right\}\right) &=\frac{1}{N_{\text {pos }}} \sum_{x, y} L_{\text {cls }}\left(\boldsymbol{p}_{x, y}, c_{x, y}^{*}\right) \\
&+\frac{\lambda}{N_{\text {pos }}} \sum_{x, y} \mathbb{1}_{\left\{c_{x, y}^{*}>0\right\}} L_{\text {reg }}\left(\boldsymbol{t}_{x, y}, \boldsymbol{t}_{x, y}^{*}\right)\\
&+L_{\text { centerness }^{*}}
\end{aligned}
$$
$L_{cls}$为分类损失采用Focal Loss(可以改善类别不平衡问题),$L_{reg}$为回归损失采用IoU loss,$L_{\text{centerness}}$采用BCEloss,是为了减少低质量的预测框(没引入超参数)。其中:
$\boldsymbol{p}_{x, y}$:80D向量,表示分类标签
$\boldsymbol{t}_{x, y}$:4D向量$(l,t,r,b)$,表示边框位置
$N_{pos}$:positive samples的个数,前向传播中,$p_{x,y}>0.05$的为positive sample
$\text { centerness }^{*}=\sqrt{\frac{\min \left(l^{*}, r^{*}\right)}{\max \left(l^{*}, r^{*}\right)} \times \frac{\min \left(t^{*}, b^{*}\right)}{\max \left(t^{*}, b^{*}\right)}}$,$\lambda=1$
回归目标 $\rightarrow$ 预测时使用
$l^{*}=x-x_{0}^{(i)} \quad, \quad t^{*}=y-y_{0}^{(i)}\rightarrow$ $\hat{x}_{0}^{(i)}=x-l^{*}, \quad \hat{y}_{0}^{(i)}=y-t^{*}$
$r^{*}=x_{1}^{(i)}-x, \quad b^{*}=y_{1}^{(i)}-y\rightarrow$ $\hat{x}_{1}^{(i)}=r^{*}+x, \quad \hat{y}_{1}^{(i)}=b^{*}+y$
特征图上的GT信息都是转换到对应的原始图像上的点进行计算的,根据实验结果取整时并未对检测结果产生影响mmdet版本代码上引入了尺度估计因子Si。
回归里的$exp(S_ix)$是什么意思?
闫jq师兄:在回归过程中,通常会为了简化训练将回归值转换为指数函数的形式。而这里的Si是为了解决使用相同结构的头结构在不同大小特征映射图上估计偏移量时存在的问题(特征图步长越大,上面预测得到的偏移量也应该相应的变大,而这会使得头结构参数值的训练变化较大而难以收敛)。通过一个可学习的尺度因子,从而使得不同大小特征映射图上估计出的x差别不会太大,而是根据Si的不同来实现不同特征层上学习到的偏移量大小的差别。
-具体细节
-
对第i层的特征和相对于原图的步长s,在第i层上的每个坐标映射到原图为中心,取xs+s//2确定位置,如果中心在真实目标框内,就会被赋值为其类别,否则为负样本(0)(图3提到,只用ground truth中间区域为positive效果更好)。同理,回归目标也是转换到对应的原始图像上的点得到的。
康hk:这里映射进行了取整操作,这样的操作对检测效果有没有影响,影响大不大?
我觉得会有影响吧??
-
康hk: 通过限制回归范围要满足 mi-1≤max(li, ti, ri, bi) ≤ mi ,使得不同尺寸的框在不同的层级进行回归,减少重叠,少量的重叠则采取 ” 使用面积最小的框 ” 的策略,其中 mi∈ (0, 64, 128, 256, 512,
∞) ,但是,为什么取这些值,有什么原因 ?闫jq师兄:这里mi值的确定是通过之前的实验经验来确定的,在已有的通用物体检测框架上,通常会选择这几个数值来对P3到P7上检测物体的大小进行限定,可以实际计算下,这里可以基本保障物体在对应特征图上(除了P3)所占像素数宽高最小为4像素最大为8像素,像素值保持在这个范围内有利于使用现有框架结构提取有效判别特征
-
在训练阶段,文中使用ResNet-50作为backbone网络,超参数与RetinaNet中一致,使用SGD优化器,初始学习率为0.01,batch_size=16,在迭代60K和80K时的weight_decay分别为0.0001和0.9,使用ImagNet预训练权重进行初始化,将输入图片裁剪为短边不小于800,长边不小于1333大小。整个网络是在COCO数据集上面训练得到的。
-大的创新
-
center-ness(vs. IoUNet)都是为了抑制低质量的预测
仅用于预测阶段。没有超参数,将AP提升了约4个点,注意由图4结果可知center-ness分支必须与回归分支分开才能有提升。
康hk Q:为什么 classification 和 center-ness 并行?这样做为什么有用?
闫jq师兄 A:并行可以实现部分头结构(即head中的卷积)的复用,从而减少模型大小和参数数量。同时,中心性在一定程度上可以为分类置信度的大小提供信息(中心度越大的情况下,分类置信度相对可以越高),两类任务彼此互补。
康hk Q:如果将 center-ness 分支去除,将其作为 regression 分支损失函数的一部分可否有效?
闫jq师兄 A:这个问题原文中有进行实验,可以再详细看一下

