图神经网络3-应用:零样本动作识别-AAAI 2019
用GCN做视频的零样本动作识别
论文:I Know the Relationships: Zero-Shot Action Recognition via Two-Stream Graph Convolutional Networks and Knowledge Graphs
代码:https://github.com/junyuGao/Zero-Shot-Action-Recognition-with-Two-Stream-GCN
1. 任务介绍
零样本动作识别,提供一些已知类和已知类上的训练样本,要把从已知类学习到的知识迁移到未知类。比如,一个小孩只看过打羽毛球的视频并知道这是打羽毛球,告诉他如果使用像羽毛球一样的球拍,使用棒球一样的球,就是打网球,之后当他第一次看到打网球的视频就已经可以认出这是在打网球。这里最核心的问题就是,如何建模已知类和未知类之间的关系。另外视频识别另一个挑战是时序建模。
已有方法及想法提出:
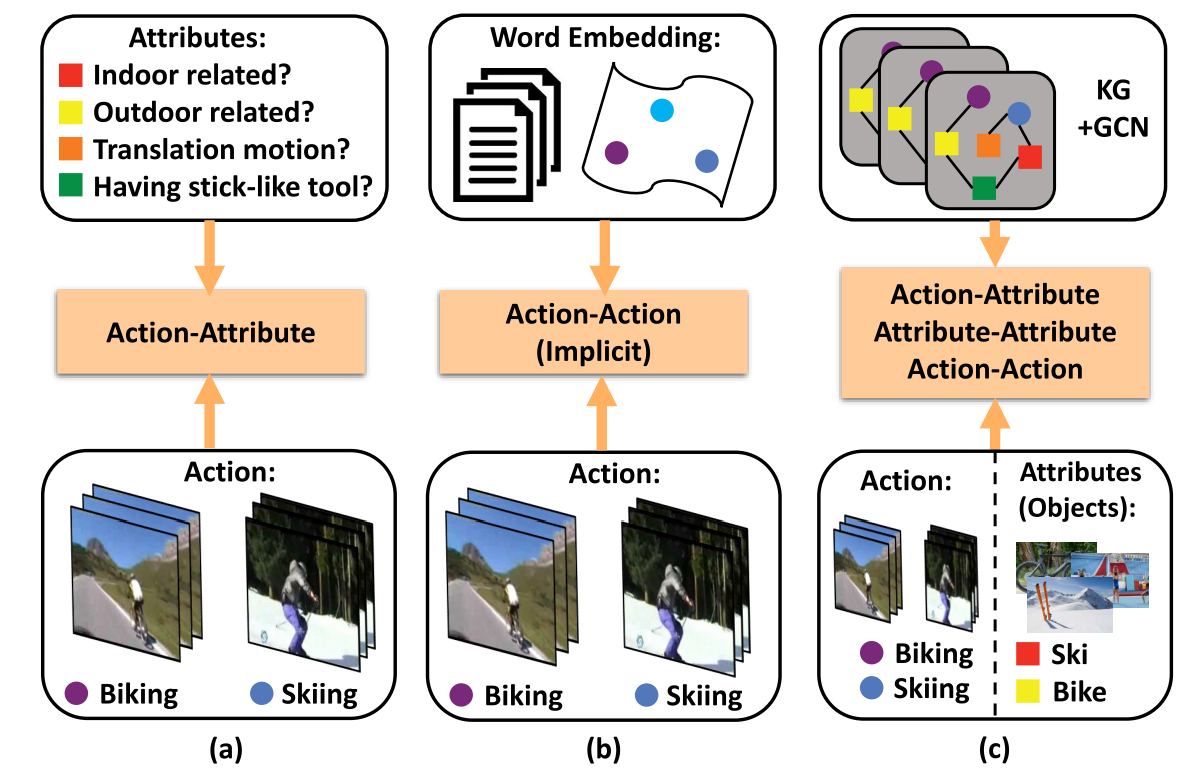
- 图a,基于属性的框架(Attribute-based framework):对视频动作人为标注一些属性,根据动作类别和属性的关系,将已知类上训练好的分类器用到未知类上预测视频的动作。(根据查到的一些博客,我的理解是,比如,整体网络分三层,第一层是输入的视频,第二层是属性,第三层是动作,输入视频经过神经网络得到各个属性的得分,再根据属性得分确定动作类别)这样的方法存在的问题:只用了属性和类别的关系;属性难定义,属性不适用于所有的视频类别导致泛化性差。
- 图b,基于词嵌入的方法(Word embedding-based framework):把动作名称的word2vec向量映射到隐空间,在隐空间隐式的建模已知类和未知类的关系,学习到一个迁移矩阵。(暂时没查到好的解释,我的理解是,通过网络学习一种输入视频到动作词向量的映射)存在的问题:只用到了word2vec信息,没用到属性等信息;动作和动作之间的关系是隐式的。
- 图c,本文的方法,通过知识图谱+GCN,建模类别和类别、属性和属性、类别和属性三种关系。这里的属性使用的是图中出现的物体。
2. 本文方法
使用双支GCN结构,上面是分类分支,下面是实例分支。
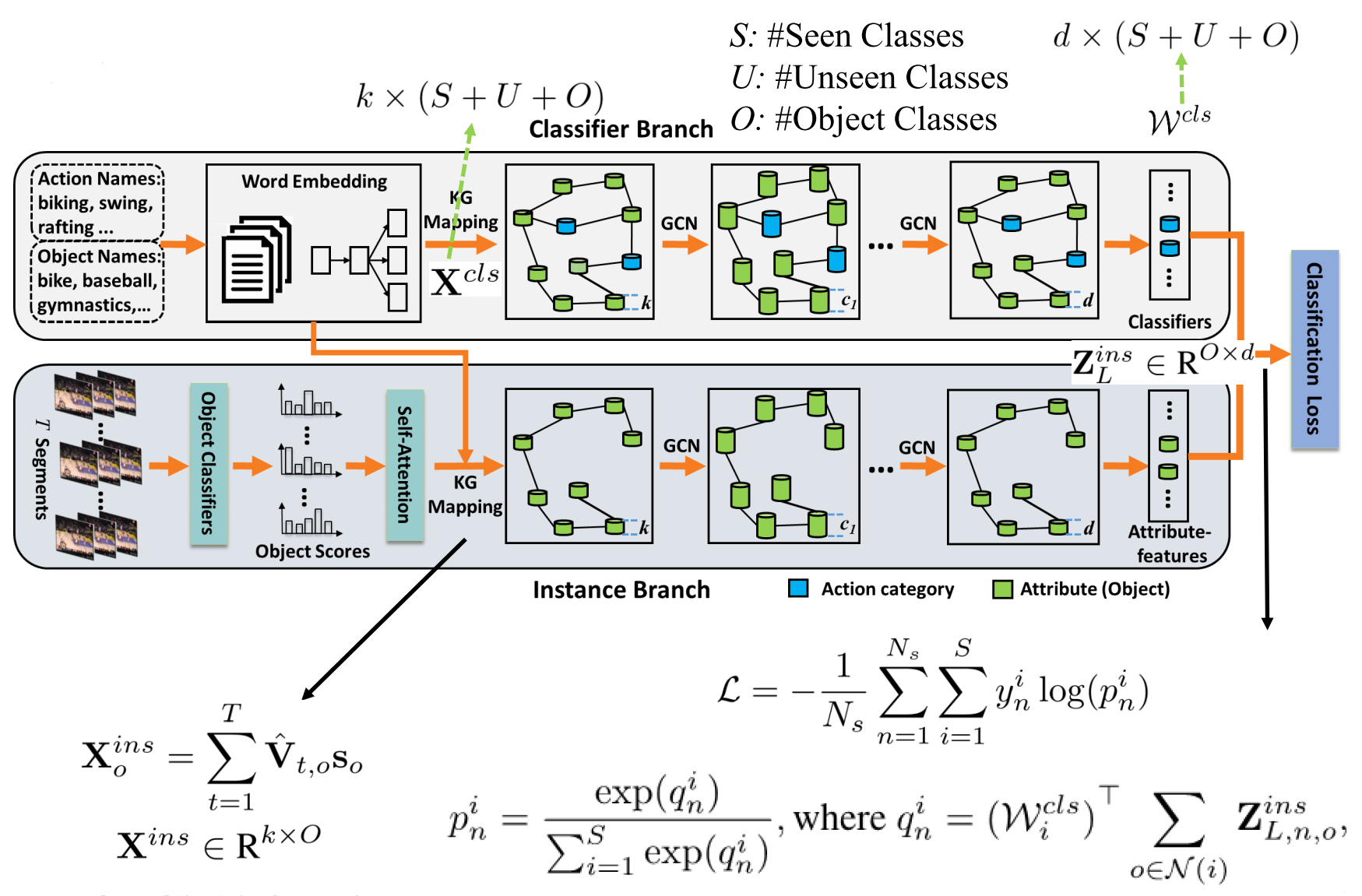
分类分支旨在构建action和objects/attribute之间的关系,其把S个可见类的action name和U个不可见类的action name以及O个object name通过word embedding(skip-gram网络),把每一个word都转换为一个 k=500 维的特征向量。然后通过现成的ConceptNet 5.5知识图谱(WebAPI),构建一个有$(S+U+O)$个结点,每个结点为k维向量的graph,结点之间有带权重的边,权重表示知识图谱中两个结点的距离。即GCN输入特征$X^{cls}$的维度为$k\times (S+U+O)$。图中蓝色的圆柱体表示action的种类,绿色的表示attribute(object)。通过三层GCN(2048-1024-512),最终输出一个矩阵:$d\times (S+U+O)$。这里的d为512维。
实例分支旨在为视频实例提供attribute-feature。首先因为视频是个序列数据,这里对于每一个video,作者都划分了T(T=16)个等长的片段 $\{V_t\}^T_{t=1}$ 。然后对于每一个片段,对上面提到的 O个obejects的每一个object打一个相关性的分数,即object score,这里使用的是GoogLeNet(O个objects的选取:对每个action选topK(K=100)个objects),片段的得分是片段中每一帧得分的均值。因此对于每一个视频V,都可以表示成一个$O\times T$ 的矩阵。为了保留视频的时序信息,作者还引入了一个self-attention操作,通过下面的公式,来找到对于任一片段 $V_s$ ,其他所有片段$\{V_t\}^T_{t=1}$ 对其的贡献 $\alpha_{s,t}$ 。self-attention的图示如下:
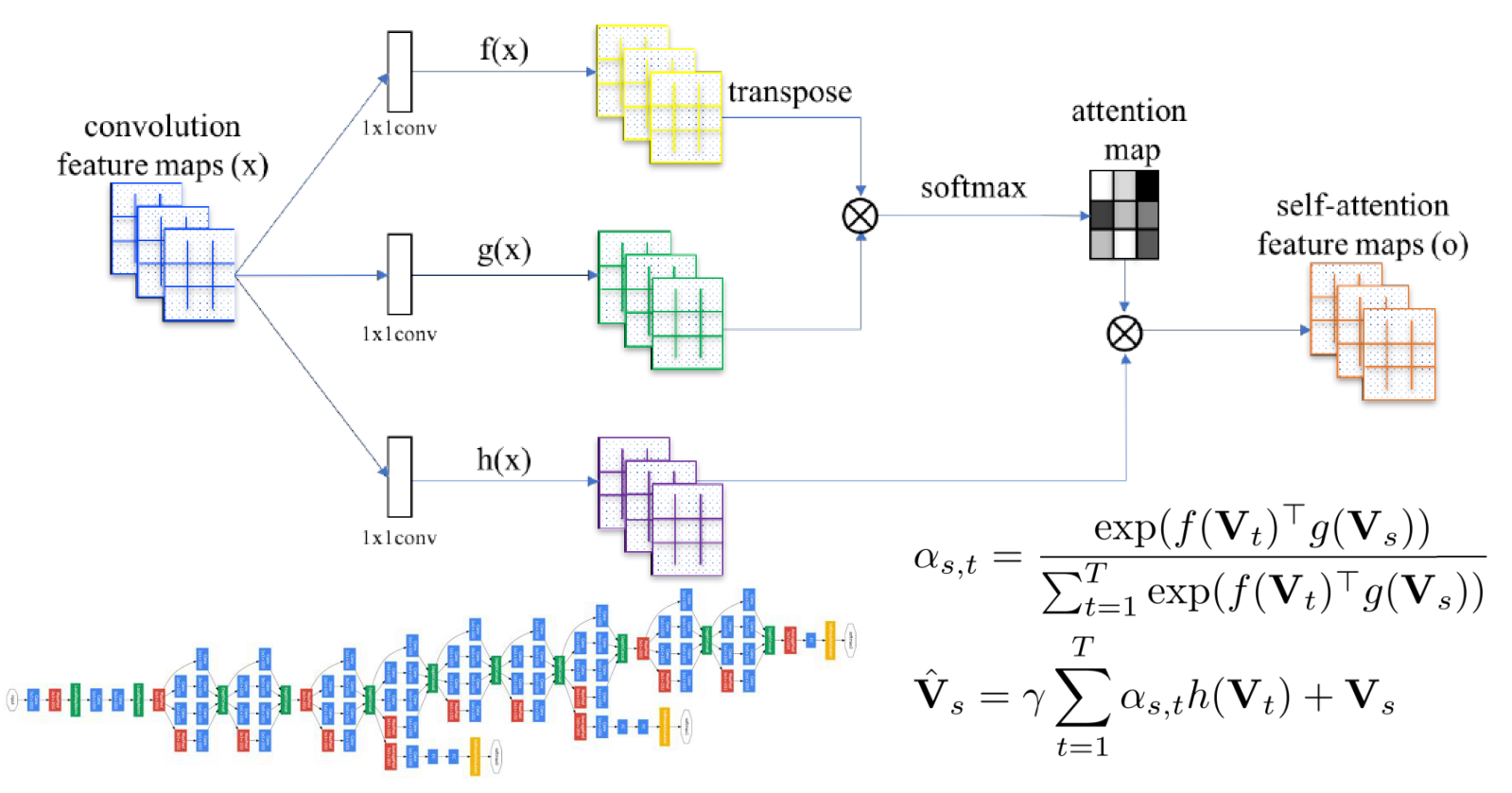
$V_t$和$V_s$表示视频第t和第s个片段的obejects得分,f(),g(),h()是三个1x1的卷积。
通过上面的操作,就可以得到一个和 $V$ 同维度的特征表达 $\hat V$ 了。这之后,把 $\hat V$ 和object 的word-embedding向量 $\left\{s_{o}\right\}_{o=1}^{O}$ 相乘构成 graph的特征,即$\mathbf{X}^{i n s} \in \mathbf{R}^{k \times O}$ ,$X^{ins}$的第o列为: $\mathbf{X}_{o}^{i n s}=\sum_{t=1}^{T} \hat{\mathbf{V}}_{t, o} \mathbf{s}_{o}$
实例分支中的图一共O个结点,每个结点为一个 k=500 维的特征向量。通过3层GCN(2048-1024-512),最终输出一个矩阵:$d\times O$,通过该实例分支,对于每一个视频,我们都能得到其对应的鲁棒的attribute-feature。
网络训练,对于所有已知类的样本,采用交叉熵损失。
$\mathcal{L}=-\frac{1}{N_{s}} \sum_{n=1}^{N_{s}} \sum_{i=1}^{S} y_{n}^{i} \log \left(p_{n}^{i}\right)$,其中$N_s$为已知类样本个数,$y_n^i$是ground-truth label,是个二值(0/1),表示 第n个 video样本是否属于第i 个已知类。 $p_n^i$ 是第n个 video样本属于第i类的概率,它由两个分支预测出的分数经过一个softmax得来:$p_{n}^{i}=\frac{\exp \left(q_{n}^{i}\right)}{\sum_{i=1}^{S} \exp \left(q_{n}^{i}\right)}, \text { where } q_{n}^{i}=\left(\mathcal{W}_{i}^{c l s}\right)^{\top} \sum_{o \in \mathcal{N}(i)} \mathbf{Z}_{L, n, o}^{i n s}$,其中$W_i^{cls}$是由分类分支产生的第i个动作类别的矩阵,$Z^{ins}_{L,n,o}$为实例分支产生的最终特征,表示第L层第n个视频第o个物体的特征,$N(i)$表示第i个action在知识图谱中的一阶object邻居。
使用ADAM优化器,学习率为0.0001,weight decay=0.0005。训练5epoch,batchsize=48.
图卷积操作,使用公式 $\mathbf{Z}=\hat{\mathbf{D}}^{-\frac{1}{2}} \hat{\mathbf{A}} \hat{\mathbf{D}}^{-\frac{1}{2}} \mathbf{X}^{\top} \mathbf{W}$,其中$\hat A=A+I$,A为带权重的邻接矩阵,I为单位矩阵,$\hat D$为$\hat A$的度矩阵,X为特征矩阵,W为要学习的参数矩阵即我们CNN中所说的卷积核。假设图中有m个节点,每个节点有k维特征,则$\hat D$和$\hat A$都是$m\times m$的矩阵,X为$k\times m$的矩阵,W应该为$k\times c$的矩阵,c为输出特征Z的通道数。每个图卷积单元都由一次卷积计算接一个非线性操作如LeakyReLU组成。
综上,分类分支构建了所有已知类和未知类的action和objects/attribute之间的关系,通过已知类的监督信息来让网络知道对于某个action,与他相关的objects,或者说,对于某些objects,其对应的action是什么。而实例分支,则是建立video和objects的关系。输入一个video序列,我们要找到里面涉及到哪些objects。当我们遇到一个新的action类的video时,我们先用实例分支找到与他最相关的objects,然后在分类分支中的知识图谱里去找这些objects对应的Unseen类的action是什么,就完成了零样本动作识别。

